🚀📊 $MU 纽约 1000 亿美元超级工厂,只是开始:美国正在重建完整 #AI 半导体技术栈
我更愿意把这条消息理解为一个信号,而不是一条单点新闻。
$MU 宣布在纽约建设价值 1000 亿美元的先进存储器超级工厂,表面上看是“内存回流美国”,但真正值得关注的是——美国正在系统性重建从 AI 设计到制造、再到封装的完整本土技术栈。
内存只是其中一层。
真正的变化,发生在整个 AI 产业链的纵深布局上。
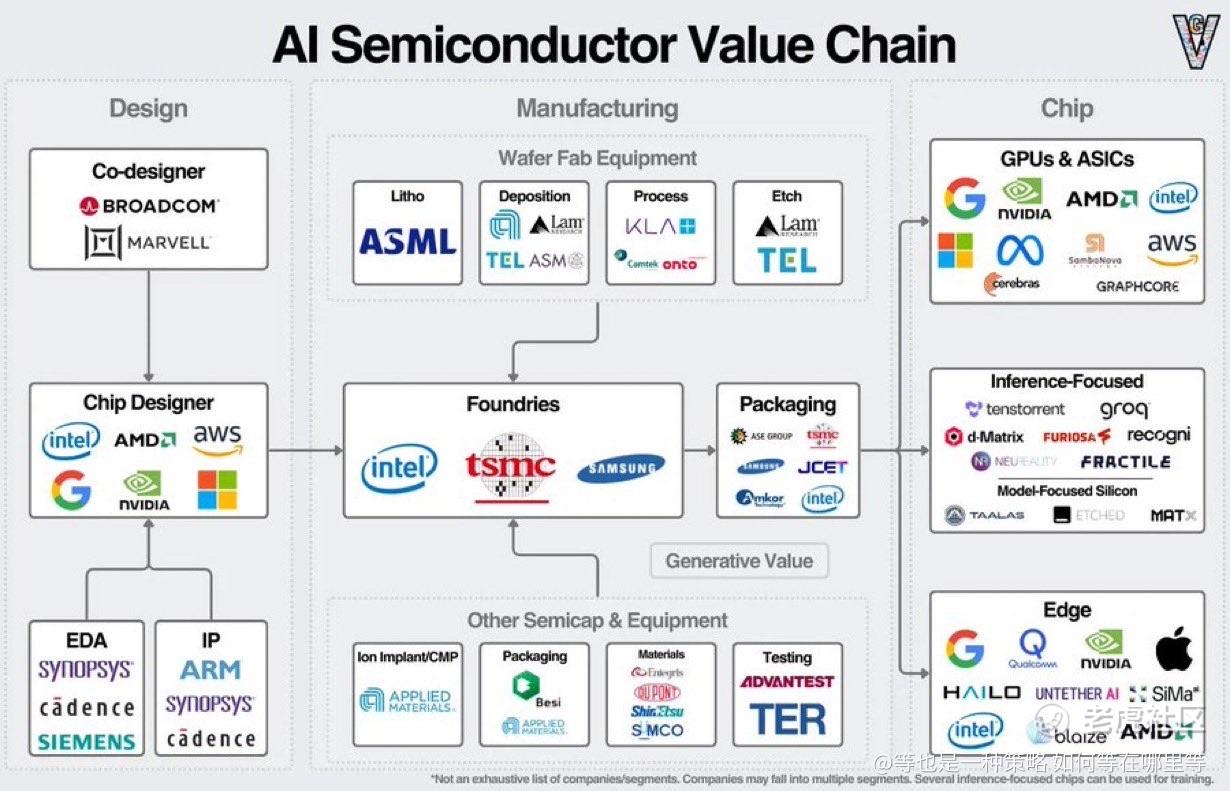
首先是 AI 芯片设计层。
$NVDA 依然是训练端的事实标准,并持续向推理端渗透。
$AMD 的意义不只是性能,而是为 AI 经济提供“第二套 GPU 体系”,避免系统性单点风险。
$GOOGL 用 TPU 把 AI 工作负载内化,本质是在用架构换毛利率。
$AMZN 通过 Trainium 与 Inferentia,直接把 AWS 的推理成本掌握在自己手中。
$MSFT 正在用自研芯片,把 Azure 的 AI 从软件堆栈一路向下打通。
$INTC 同时押注 CPU、加速器与制造,目标不是短期性能,而是长期产业控制权。
接下来是 AI 芯片的联合设计者,这是过去几年最容易被低估的一层。
$AVGO 正在与超大规模数据中心共同定义“为特定工作负载而生”的定制 AI 系统,把计算、内存、网络融合成一体。
$MRVL 则专注在高速互连与定制加速器,让 AI 训练与推理真正跑在系统级最优解上。
然后是 边缘 AI,也是 AI 从“云端概念”走向“真实渗透”的关键。
$AAPL 选择把推理直接塞进消费级设备,让 AI 成为硬件体验的一部分。
$QCOM 把低功耗 AI 推向移动与边缘终端,这是规模化应用的前提。
很多人忽略,但真正的护城河往往在最上游——EDA 与 IP。
$SNPS、$CDNS 是所有先进 AI 芯片诞生前必须经过的“关卡”。
$ARM 的 CPU 架构,早已嵌入数据中心、边缘与移动 AI 的核心位置。
再往下,是 制造权本身。
$TSM 仍然是整个 AI 堆栈无法绕开的制造核心。
$INTC 的角色越来越清晰——不是替代台积电,而是成为战略级第二来源。
而在晶圆制造设备层,话语权更加集中。
$ASML 是真正的“造王者”,没有它,先进节点根本不存在。
$LRCX、$KLAC、$TEL 分别从工艺形成、良率控制到关键制程,构成先进 AI 芯片量产的底座。
$AMAT、$TER 则覆盖材料、封装前段与测试验证,确保规模化交付。
最后,别忘了 先进封装。
$AMKR 正处在最容易被忽视、却最关键的位置——把 GPU 与 HBM 真正整合成一个可落地的 AI 计算系统。
当你把这些拼在一起看,$MU 的超级工厂就不再是孤立事件。
它是一个信号:
AI 不再只是模型与算力的竞争,而是国家级“全栈控制力”的博弈。
问题来了:
在这一整条链路中,你更看重“架构定义者”,还是“制造与设备的隐形垄断者”?
📬我会不定期分享具备10倍成长潜力的交易机会,并聚焦 $TSLA、AI、能源转型等核心公司与技术趋势的中长期演变。
欢迎订阅,一起在下一轮科技浪潮启动前完成前瞻性布局。
$MU $NVDA $AMD $GOOGL $AMZN $MSFT $INTC $AVGO $MRVL $AAPL $QCOM $SNPS $CDNS $ARM $TSM $ASML $AMAT
#AI #Semiconductors #ArtificialIntelligence #Chips #USManufacturing #DataCenter #AdvancedPackaging
精彩评论