
中国大模型不只便宜,更在编程与智能体场景里打穿全球市场。
2026年春节后,一组来自OpenRouter的最新数据在全球开发者圈刷屏:在平台前十模型中,中国大模型拿走了61% 的 Token 使用量,前三名全部是国产模型。
其中,来自 MiniMax 的MiniMax M2.5一周内被调用了约2.45 万亿个 Token,直接登顶全球第一。
这并非偶然事件,而是中国 AI 在价格、性能、场景三条战线上的集体爆发。
01 谁在封神?中国模型拿下61%份额
OpenRouter是由前 OpenSea CTO Alex Atallah 创立的多模型聚合平台,接入了全球60多家提供方的400多个模型,是开发者调用大模型的重要入口。
根据2026年2月24日的最近一周数据:
平台前十模型共消耗约8.7 万亿 Token
其中国产模型贡献约5.3 万亿 Token,占比高达61%
榜单亮点:
第1名:MiniMax M2.5,一周调用2.45 万亿 Token,周环比暴涨197%
第2名:Kimi K2.5(月之暗面),约1.21 万亿 Token,稳居前列
第3名:GLM-5(智谱 AI),约7800 亿 Token,周环比增长158%
第5名:DeepSeek V3.2 也进入前五
中国模型不只是“上榜”,而是在全球开发者的真实请求中占据了绝对主角地位。
02 为什么是它?MiniMax M2.5 凭什么冲到世界第一
1. 从参数到实战:在编码基准里逼近顶级闭源
MiniMax M2.5 定位为“为真实生产力场景设计的旗舰模型”,强调推理与工具调用能力。
在SWE-Bench Verified等编程基准测试中,其得分达约80.2%,与 Anthropic 的 Claude Opus 4.6(约80.8%)处于同一梯队,部分多任务编码基准甚至领先。
对硅谷和国内程序员而言,它已从“能用”变为“敢用、好用”的级别。
2. 智能体原生设计:为“Agent时代”量身打造
据 AIBase 与证券机构分析,MiniMax 官方将 M2.5 定位为“首个面向 Agent 场景原生设计的生产级旗舰模型”。
发布后一周内,其 Token 使用量就突破了3.07 万亿。
这类模型在多步骤推理、工具调用、长任务状态管理等方面做了深度优化,非常适合“自动写代码、自动调试、自动改需求”的新一代智能体应用。
因此,MiniMax M2.5 的主要流量并非来自闲聊,而是大量真实项目中的编程与自动化工作流。
03 编程与Agent:改变Token结构的两大场景
根据多家机构对 OpenRouter 的拆分数据,过去一年 Token 使用结构发生显著变化:
编程相关场景的 Token 消耗,从早期的约10%提升至50%以上
智能体工作流已占整体输出 Token 的一半以上
这揭示了一个直观趋势:
人们不再满足于“让模型回答问题”,而是开始将其视为长期在线的自动化“员工”——写代码、跑脚本、查文档、接API,全流程自动完成。
中国模型在这两个方向上表现尤为突出:
MiniMax M2.5、Kimi K2.5、GLM-5 在代码理解、上下文保持、工具调用上均做了针对性优化
许多海外智能体平台在 AB 测试后,开始大规模切换或叠加中国模型,专门用于编码与自动化流程
一个明显现象是:中国模型在“Agent流程”中的占比,显著高于其在“普通聊天请求”中的占比。
04 价格战:国产模型“10~20倍价差”的真相
在算力成本高企的今天,“每百万Token价格”已成为核心决策因素。
主流模型价格对比(每百万Token):
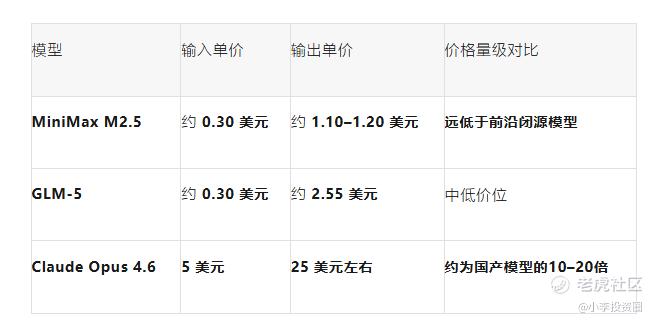
AIBase 测算显示:以输入价格为例,MiniMax M2.5 和 GLM-5 相比 Claude Opus 4.6 具有约16.7倍的价格优势。
MiniMax 官方也称,M2.5 的整体使用成本大约是 Opus、Gemini Pro、GPT 等旗舰闭源模型的1/10 到 1/20。
对需要“全天候跑Agent”的团队而言,这意味着:
同样预算,可多跑10倍以上的任务
相同规模下,极大压低服务成本,提高毛利率
价格,成为中国模型出海的重要“杀手锏”。
05 硅谷为何大规模采用中国开源/开权模型?
MIT Technology Review 及多家智库调研指出:在以硅谷为代表的创业生态中,中国开源或开权重模型正在快速渗透。
约80%的美国AI初创公司,在其开源AI技术栈中使用了中国开权重模型
MIT 与 Hugging Face 研究称,中国模型全球下载量占比已超17%,而美国模型约15.8%(两年前美国曾占60%以上)
原因非常“工程师导向”:
足够强,足够便宜:性能接近顶级闭源,成本低一个数量级
开源/开权重:易于私有化部署、结合自家数据微调,满足欧美数据合规与隐私要求
生态兼容好:在 Hugging Face、SambaCloud 等平台有完备工具链,方便集成
中国模型在硅谷的流行,不是“政治正确”,而是工程正确 + 经济正确。
06 对中国开发者的三点实用启示
1. 对AI产品创业者/程序员:
可将MiniMax M2.5、Kimi K2.5、GLM-5、DeepSeek V3.2作为“默认选项”进行AB测试,尤其在编程、Agent、多轮复杂任务上
若同时开拓海内外市场,可利用 OpenRouter 等平台一次接入、多模型切换,降低成本并优化体验
2. 对搭建智能体/自动化工作流者:
优先选择原生支持工具调用、长上下文和多轮链式推理的模型,如MiniMax M2.5、DeepSeek V3.2
在设计时充分考虑Token预算:国内模型在多轮场景的成本优势显著,可“放开用”,提升智能体尝试空间
3. 对普通用户/内容创作者:
可将此次“国产模型登顶”视作一个强烈信号:中国AI不再只是“追赶者”,而是在真实市场中获得了“用脚投票”的认可
07 2026年:中国AI的真正拐点?
OpenRouter 数据显示,平台整体每周Token消耗已达约12.1万亿,同比增长超十倍。全球对大模型的需求正进入“指数级膨胀期”。
在此时间点,中国模型不仅在国内卷出新高度,更在海外实打实地拿到了市场份额与开发者心智。
对中国开发者和创业者而言,2026年很可能是一个“别再只做下游应用”的拐点:
上游模型已具备全球竞争力
中游工具链正在加速成熟
下游产品若能吃透编程与Agent场景,便有机会直接服务全球用户
机遇就在眼前,关键在于能否抓住。
精彩评论