
在AI大模型时代,算力被视作“新石油”。但越来越多的迹象表明,单个GPU的性能已经不再是决定性变量。
模型规模正以指数速度膨胀,训练和推理需要成千上万颗GPU同时工作,而这一切的效率,最终取决于它们之间的互连网络。
英伟达显然比大多数竞争者更早看到了这一趋势。它不仅在GPU性能迭代上占据领先,更通过NVLink、InfiniBand与Spectrum-X等技术,重新定义了算力系统的架构逻辑。
GPU之间的数据传输不再是简单的“带宽问题”,而是系统整体效率的核心瓶颈。延迟过高、拓扑不优,都会导致算力资源的浪费,甚至让性能提升停滞。
这也是为什么,英伟达在过去十年里不断加码网络层战略:从芯片到互连,再到系统级整合,逐步构建起一个难以被轻易替代的护城河。在这个过程中,互连从幕后走向前台,成为决定AI算力演进的新核心。
Part 1
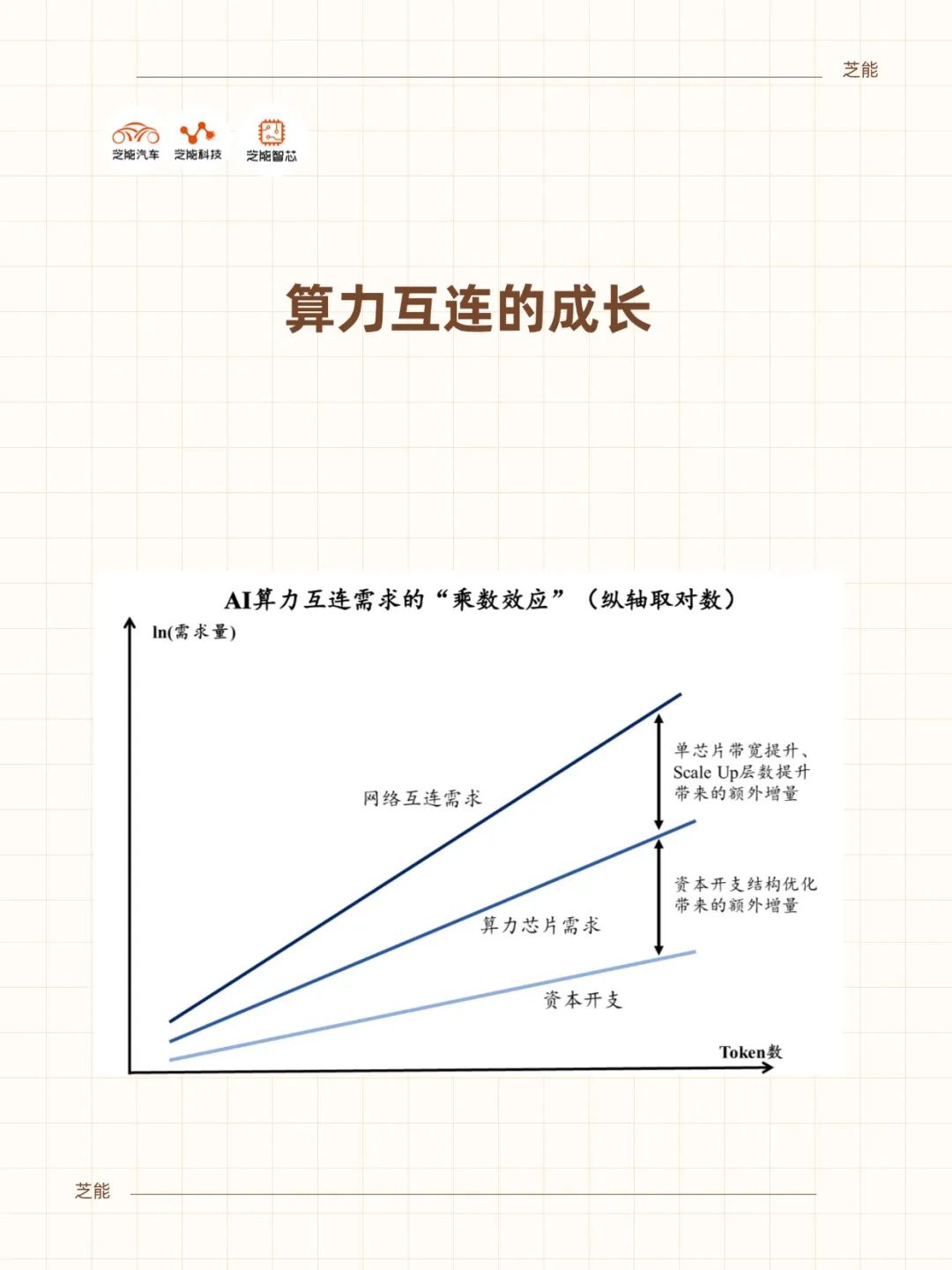
算力需求爆发
与互连架构的核心地位
人工智能模型规模的扩张,推动了算力需求的指数级增长。从参数数量的快速累积,到训练数据量和推理场景的多样化,单一芯片性能的提升已难以满足整体需求。
为此,算力系统必须通过集群化方式进行扩展,而这也将互连架构推向舞台中央。
英伟达在GPU设计中长期强调并行计算优势,但当计算规模达到数万甚至数十万颗GPU协同时,互连效率就成为性能瓶颈。延迟、带宽和拓扑结构的优化,直接决定了算力集群的利用率和大模型训练的效率。
这也是为何英伟达不仅专注于GPU芯片的迭代,同时在NVLink、InfiniBand和Spectrum-X以太网等互连技术上持续布局。
在当下的AI训练与推理任务中,芯片性能提升与互连架构升级必须同步,否则会出现算力无法充分释放的情况。
尤其是在“Scale Up”趋势下,互连网络的效率将与“Scaling Law”类似,呈现出与模型精度、计算资源之间的耦合关系。换言之,算力的扩展不再只是单个GPU的战斗,而是系统协同的整体效率。
英伟达的算力战略,展现出一个从硬件到网络的完整闭环。其核心逻辑在于,通过自研的互连架构,将GPU性能最大化释放,并形成难以被轻易复制的生态优势。
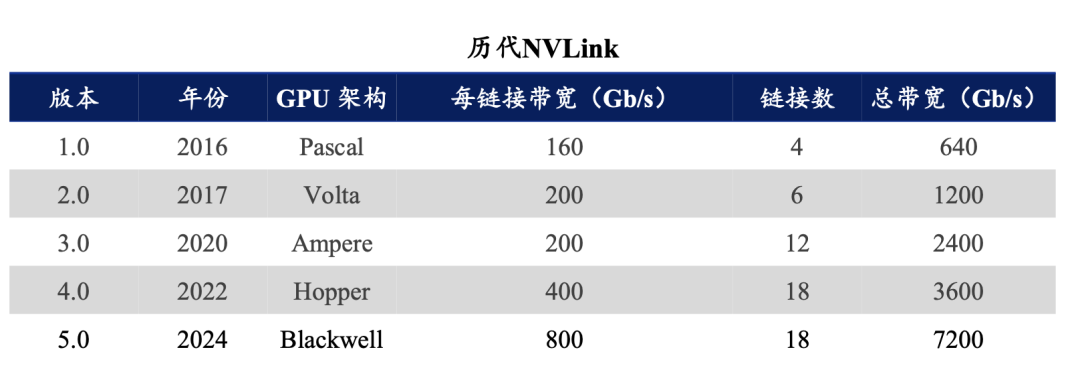
NVLink作为GPU间高带宽低延迟的直连技术,使得多个GPU能够像“单一超级芯片”般协同工作。在Hopper架构与GH200等平台中,NVLink的迭代使得GPU之间的数据传输速度成倍提升,极大缓解了多卡并行的通信瓶颈。
面向更大规模的集群,英伟达通过收购Mellanox,掌握了InfiniBand与高速以太网的核心技术。InfiniBand凭借其成熟的网络堆栈与高效的拓扑优化,成为AI超算中心的首选。而Spectrum-X则针对AI工作负载对以太网进行了深度定制,以满足推理和训练不同阶段的差异化需求。
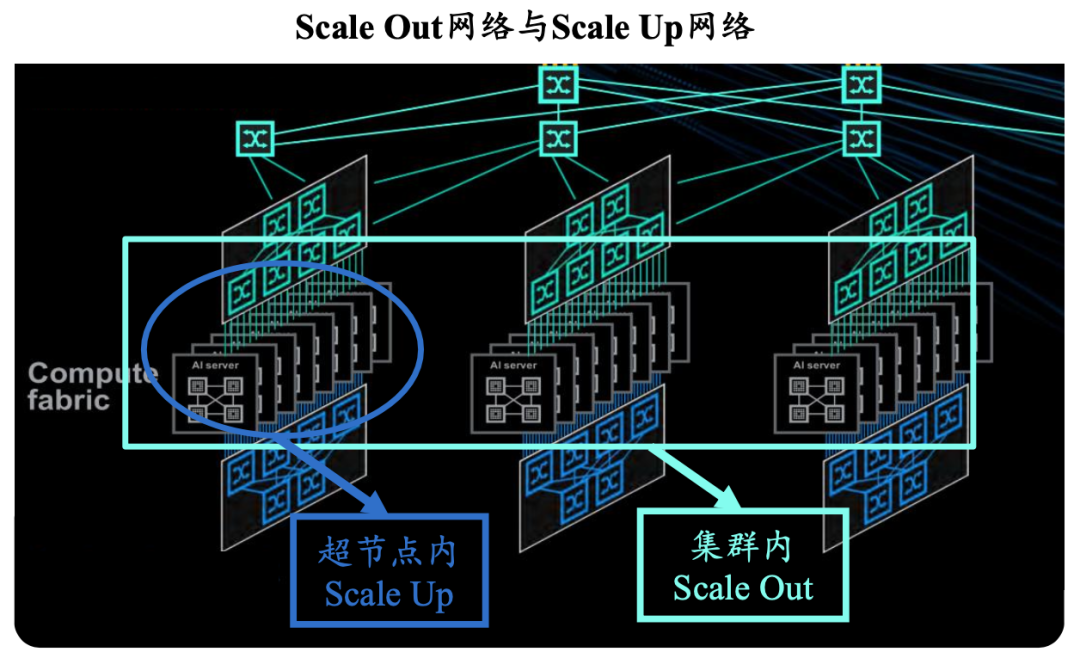
这种“芯片+互连+系统”的战略,意味着英伟达在AI算力基础设施上形成了垂直整合优势。GPU算力的迭代与互连网络的升级同步进行,不仅保证了技术领先性,也让用户更容易在其生态内形成路径依赖。
从产业角度来看,互连板块的成长性,实际上与AI大模型的迭代节奏紧密相连。每一次模型规模的扩大,都要求互连架构提供更高的带宽、更低的延迟与更优的拓扑效率。这意味着,互连设备与解决方案将与GPU一样,成为算力体系不可或缺的核心环节。
Part 2
Scaling Law
在网络层的延伸逻辑
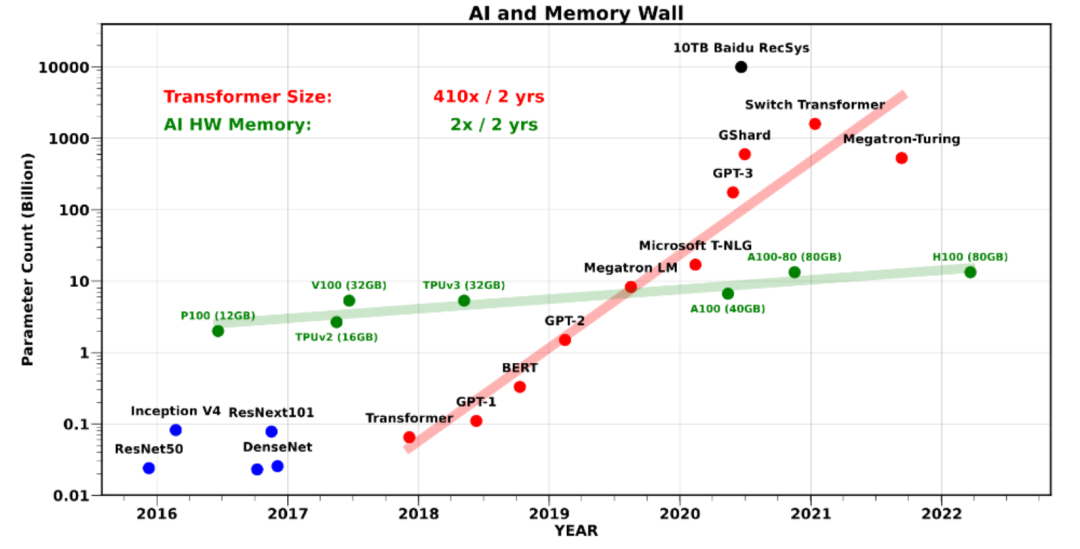
AI的发展遵循“Scaling Law”,即随着算力、参数量和数据规模的增加,模型的性能会呈现规律性提升。
在过去,这一规律主要被理解为“GPU数量+模型规模”的函数关系。然而,当集群规模不断扩大,互连效率本身也开始成为Scaling Law的变量之一。
如果互连带宽不足,延迟居高不下,GPU算力的增加可能并不会带来线性收益,反而会因为通信瓶颈导致利用率下降。反之,当互连性能同步提升时,模型在精度与收敛速度上就能接近理论上限。
可以将互连效率视作Scaling Law中的“隐藏参数”。它决定了算力扩展是否能够真正兑现为模型性能提升。
从这一角度看,英伟达对NVLink和InfiniBand的重视,并不是锦上添花,而是维持Scaling Law持续生效的必要条件。
当大模型规模继续突破万亿参数级别时,互连网络的线性扩展能力甚至可能直接决定AI发展的上限。这也为互连技术的长期成长提供了逻辑支撑。
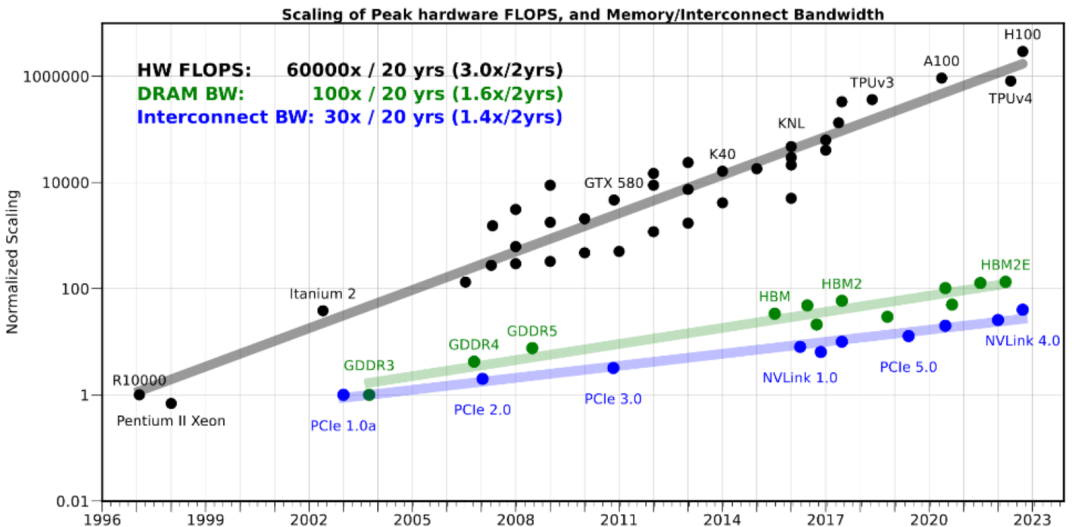
互连板块的成长性不仅体现在GPU厂商本身,也在于整个产业链的广阔机会。
其价值链条覆盖芯片、模组、光电材料与系统设备等多个环节。在芯片环节,负责高速交换与数据调度的互连芯片需求快速增长。随着带宽翻倍与低延迟要求的提升,交换芯片、SerDes芯片成为关键增量市场。
在光模块环节,大规模AI集群对高速光模块需求爆发。400G/800G光模块已成为主流,未来1.6T光模块也在加速研发。光模块厂商因此迎来直接受益。
在材料环节,高速互连需要更低损耗、更高频率的PCB与CCL(覆铜板)。
先进封装与低介电损耗材料成为必需,为上游材料企业创造新空间。在系统设备环节,交换机、路由器与整机互连方案同样受益于带宽升级。大型数据中心与AI集群的部署,将直接拉动高端设备需求。算力互连不仅是GPU厂商的护城河,也是整个硬件产业链的新增长极。
小结
英伟达的逻辑是:当AI走向“超级规模”,算力竞争就必须转向系统效率竞争。互连不只是GPU的“辅助”,而是释放整体算力的关键变量。
“Scaling Law”曾揭示了参数规模与模型精度的关系,那么在网络层,它可能同样成立:互连性能的提升,将与模型效果形成正反馈,推动AI进一步扩展。未来的算力基础设施是GPU、互连与系统架构的整体博弈。
精彩评论