
AI大模型的训练速度,越来越取决于网络带宽,而不是单颗芯片的性能。换句话说,算力的瓶颈正在从计算核心转移到数据流动。
Lightmatter在这一节点推出的Passage 3D CPO平台,把硅光子集成与DWDM波分复用放进了CPO的封装环境里,用16个波长把一根光纤的吞吐能力推到极限,再在参考平台上实现114Tbps的总带宽。这种高密度互连方式,直接回应了AI集群在空间、能效和端口数上的困境。
Passage 3D不仅仅是提高了“带宽指标”,它试图在架构层面重塑大规模集群的互连逻辑:减少铜线、压缩光纤数量、降低交换机依赖。其潜台词是,AI算力的未来增长,将越来越依赖光子而非电子。

Part 1
技术实现的核心细节
Passage 3D平台的设计核心是硅光子集成电路(PIC),它与电子集成电路(EIC)协同工作,实现光电一体化的数据传输。
这一PIC被划分为八个独立的光子模块,每个模块具备14Tbps的传输能力,总体上能提供极高的吞吐率。与传统依赖铜互连的方式相比,这种架构的优势在于更低的能耗和更好的信号保持能力。
电互连在高速传输中容易受到串扰和信号衰减限制,而光子互连则能在更长的距离上保持较高的带宽密度。

平台设计了16个外部光口,每个端口输出7.2Tbps的带宽。这些外部光口通过内部256根光纤与16个光纤耦合单元(FAU)相连,形成庞大的内部光学通道网络。
在整体上,Passage M1000参考平台能够提供114Tbps的总带宽,这是通过高效的波分复用技术实现的。

其关键技术是16波长DWDM(Dense Wavelength Division Multiplexing)。在单根光纤中叠加16个不同的波长,每个波长对应一条独立的数据信道,从而极大提高了光纤利用率。
在这种复用模式下,光纤相当于承载了16倍于传统单波长的带宽。每个波长都在纳米级的频谱间隔中传输,因此设计必须保证波长稳定,避免通道间的串扰和偏移。

硅光子平台的优势在于可以在同一芯片上完成调制器、探测器和波导的高度集成,这使得DWDM系统可以实现更小的尺寸和更好的能效。
但这也带来新的挑战。由于波长间隔较小,任何温度变化都会导致波长漂移。例如,硅的折射率会随着温度升高而发生变化,导致通道波长偏移。如果不同波长之间发生重叠,就会引起误码和信号失真。
因此,Passage 3D的设计必须在封装中引入精密的温控机制,通过热电调节器(TEC)等手段保持波长稳定。

在器件层面,PIC与EIC的协作是另一大技术难点。光子器件负责高速信号的调制与传输,而EIC则提供驱动和控制逻辑,两者之间需要低延迟、高带宽的互连。
在Passage平台中,这一结合通过先进封装实现,通常涉及2.5D中介层或3D堆叠。这意味着信号需要在电与光之间频繁转换,转换效率和损耗直接影响到系统性能。
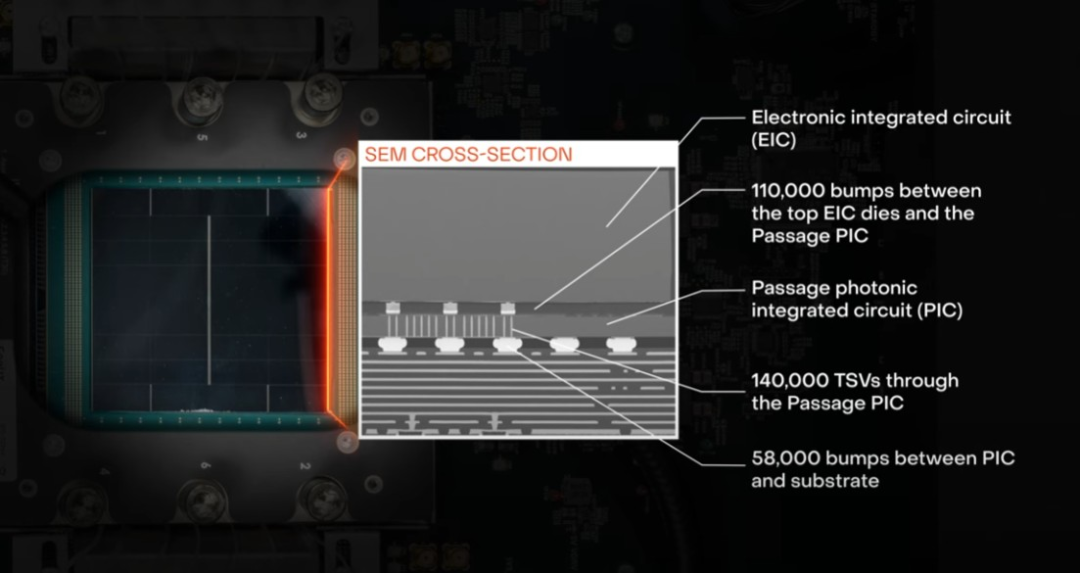
Passage 3D 将DWDM与CPO结合,通过硅光子集成和先进封装,构建出一个高密度的光互连参考平台。
Part 2
工程应用与潜在挑战

Passage 3D 展示了技术上的可行性,还直接回应了AI集群在扩展过程中遇到的实际问题。
随着GPU和专用加速器算力的提升,单节点的计算能力快速增长,但要把成千上万个节点组织成一个整体,需要依赖高效的网络互连。如果网络带宽不足,训练任务中的数据交换就会成为瓶颈,导致计算资源闲置和效率下降。

现有的高速电互连,如PCIe和以太网,在高频率下的损耗与功耗日益严重。即使是当下主流的800G光模块,也需要大量光纤与交换机端口来支撑超大规模集群。这导致机房的布线复杂度和能耗不断上升。
Passage 3D通过在单根光纤中承载16个波长,显著提升了链路的有效带宽,从而减少了光纤数量和端口需求。对于成千上万个节点的大型AI系统而言,这不仅节省了布线和交换资源,还降低了整体能耗。
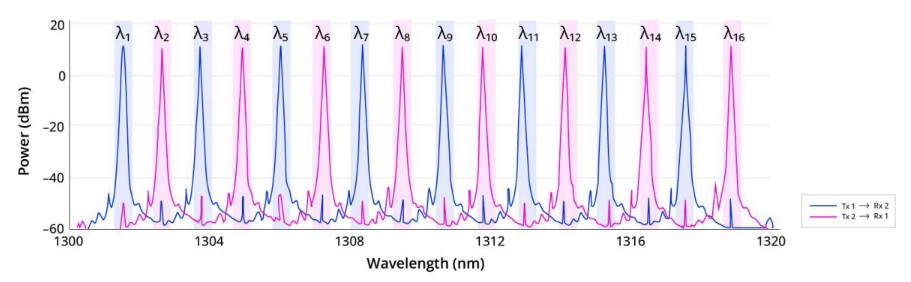
网络拓扑设计是另一层面的问题。
在传统的fat-tree或dragonfly网络中,交换机端口数量往往成为瓶颈。随着集群规模扩展,交换机的层级与数量迅速增加,导致成本和功耗呈非线性上升。
Passage 3D通过提升单纤带宽,减少了对额外端口的依赖,相当于间接优化了网络拓扑结构。这对于百万级别的XPU集群尤为重要,因为在这个规模下,网络复杂度和互连成本可能超过芯片本身的制造成本。
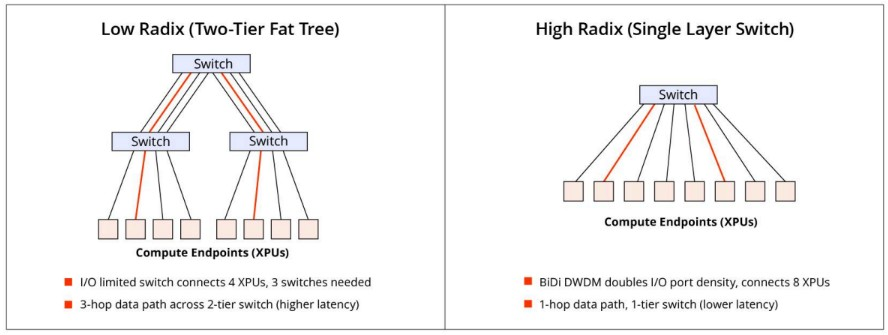
要将Passage 3D推广到量产与商用,还面临一些工程难题。
◎ 首先是波长稳定性问题。随着波长间隔缩小,温度漂移带来的影响更为显著,需要可靠的热管理和波长锁定技术。
◎ 其次是制造一致性。硅光子虽然已经有成熟的工艺,但在DWDM应用中,任何工艺偏差都可能导致通道性能下降,从而影响系统良率。
◎ 再者是系统集成的复杂度。CPO方案将光收发与计算核心紧密封装,这不仅对散热设计提出更高要求,还在可靠性和测试环节带来挑战。
DWDM信号在传输中也存在非线性效应,比如自相位调制和四波混频。
在数据中心内部虽然传输距离有限,但在高功率密度下,这些效应可能依然影响信号质量。如何在功耗、信号完整性和带宽之间找到平衡,是未来工程化落地的重要课题。
Passage 3D仍然代表了一条明确的方向:通过提高单纤带宽利用率,在相同的物理资源下实现更高效的网络互连。这对AI大模型的训练效率、能耗优化和整体系统成本控制都有重要意义。
Passage 3D的贡献在于为未来的算力扩展提供了一种现实可行的工程解法。
它既展示了硅光子与DWDM的结合潜力,也为大规模系统互连指出了一条降低资源消耗、提升能效的路径。随着AI集群规模继续扩大,这种设计有望成为主流架构的一部分。
小结
在算力不断增长的时代,互连能力往往决定了系统的上限,通过在单根光纤上承载16波长的DWDM信号,显著提升了带宽密度,并通过CPO集成减少了能耗和空间占用。
在波长稳定性、制造一致性和系统集成方面仍需进一步突破,但这一方向已经展现出足够的价值。对未来动辄百万级XPU组成的AI系统而言,互连效率或许比单芯片性能更具决定性。
精彩评论