
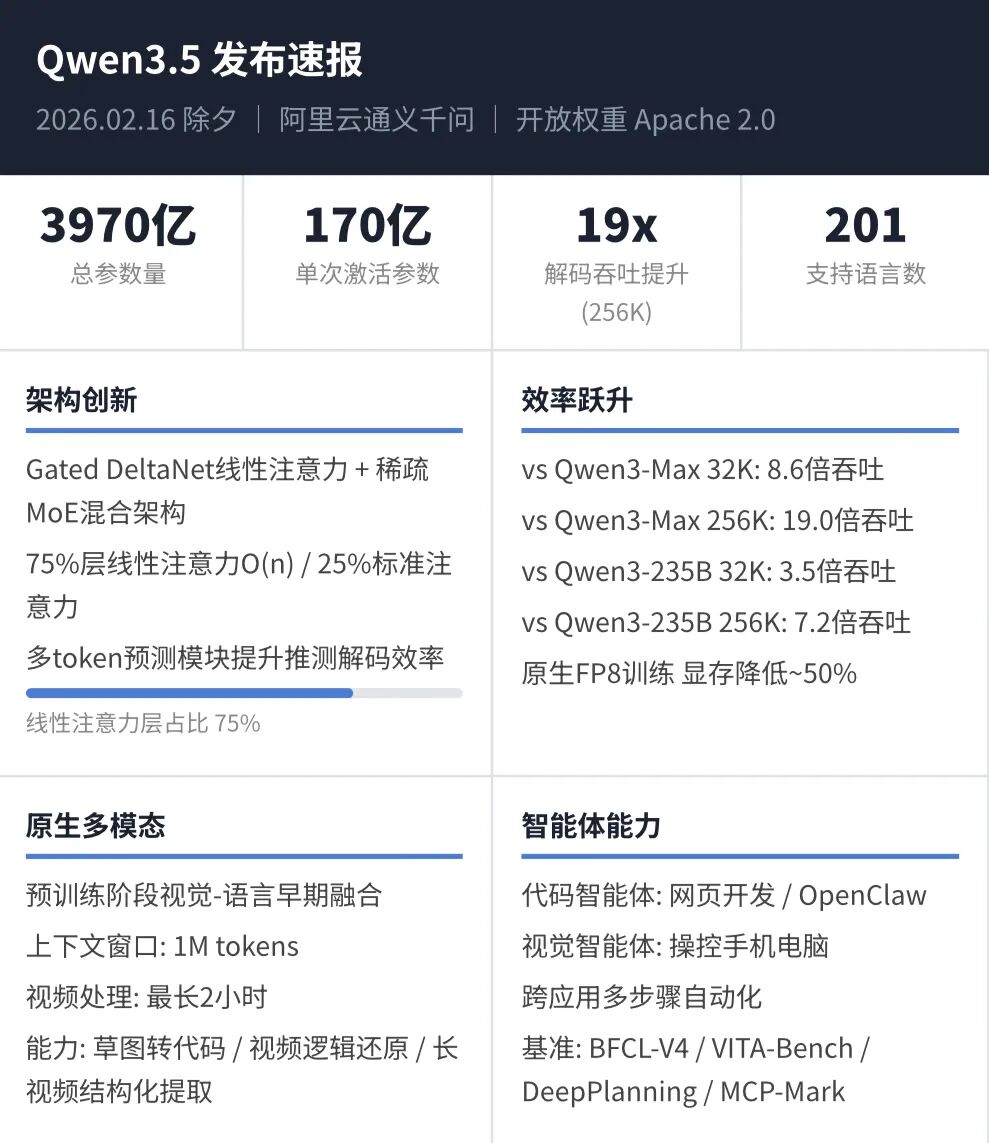
Qwen3.5最根本的变化发生在架构层面。
它采用全新的混合架构,将线性注意力Gated DeltaNet与稀疏MoE深度结合——75%的层使用线性注意力实现O(n)复杂度,25%保留标准注意力确保推理精度。
官方数据显示,Qwen3.5-397B-A17B在32K上下文下解码吞吐是Qwen3-Max的8.6倍,256K长上下文场景更达到19倍。用阿里自己的话说,这是"用小模型的成本跑出大模型的效果"。
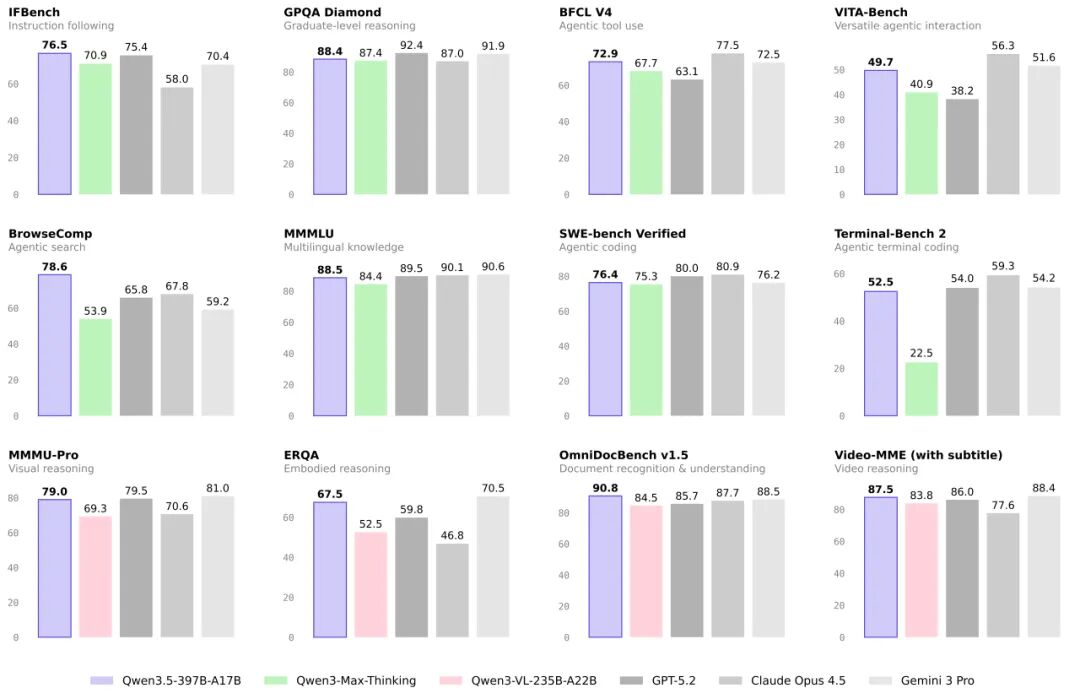
各项数据指标的详细对比。
与Qwen3最大的区别在于"原生"二字。
Qwen3.5从预训练阶段就实现了文本与视觉的早期融合("early fusion training on trillions of multimodal tokens",即在万亿级多模态token上进行早期融合训练),上下文窗口扩展至1M tokens,可直接处理长达两小时的视频内容。它能将手绘草图转化为前端代码,对游戏视频进行逻辑还原,也能将长视频自动提炼为结构化网页。视觉不再是后天拼接的附属模块,而是与语言并行的核心能力。
Agent能力的提升同样值得关注。
这一代的核心突破来自强化学习环境的全面扩展——阿里不再针对单一基准做优化,而是追求真实场景下的泛化。作为代码智能体,Qwen3.5能驱动网页开发、与OpenClaw集成完成复杂编程;作为视觉智能体,它可自主操控手机和电脑执行跨应用多步骤自动化流程。在BFCL-V4、VITA-Bench等多项Agent基准上,模型效果随RL环境规模的扩大持续攀升。
基础设施层面,Qwen3.5采用原生FP8训练流水线与异步强化学习框架,实现约50%的显存降低与3到5倍端到端加速。
多语言支持也从119种扩至201种语言和方言,词表从15万扩至25万,多数语言编解码效率提升10%到60%。
Qwen3.5的野心已经非常清晰——不做更大的模型,做更聪明的智能体。
从任务型助手进化为能长期自主运行的数字伙伴,这是通往通用智能体的关键一步。
精彩评论