
转自:中国蓝新闻
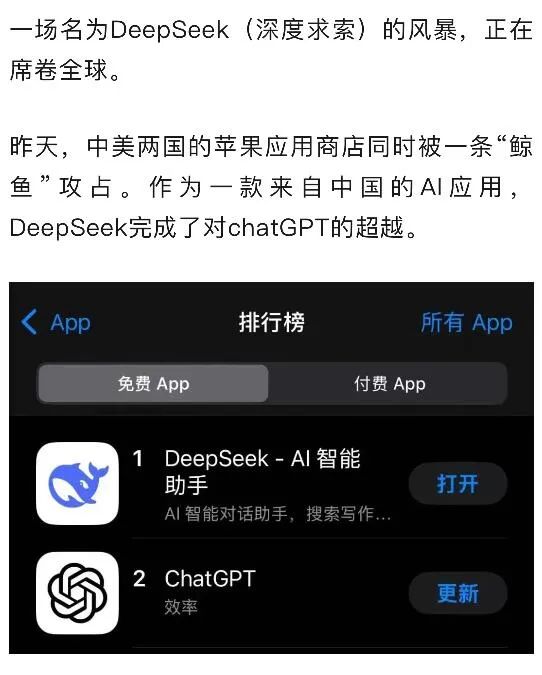



彻底释放它的,就是一个月来官宣两个开源大模型,被称为“来自东方神秘力量”的DeepSeek。他们的总部位于杭州。


1月27日,同在杭州,《黑神话:悟空》出品人、游戏科学创始人冯骥总结了DeepSeek六大特点:强大、便宜、开源、免费、联网、本土。他还说:DeepSeek,可能是个国运级别的科技成果。

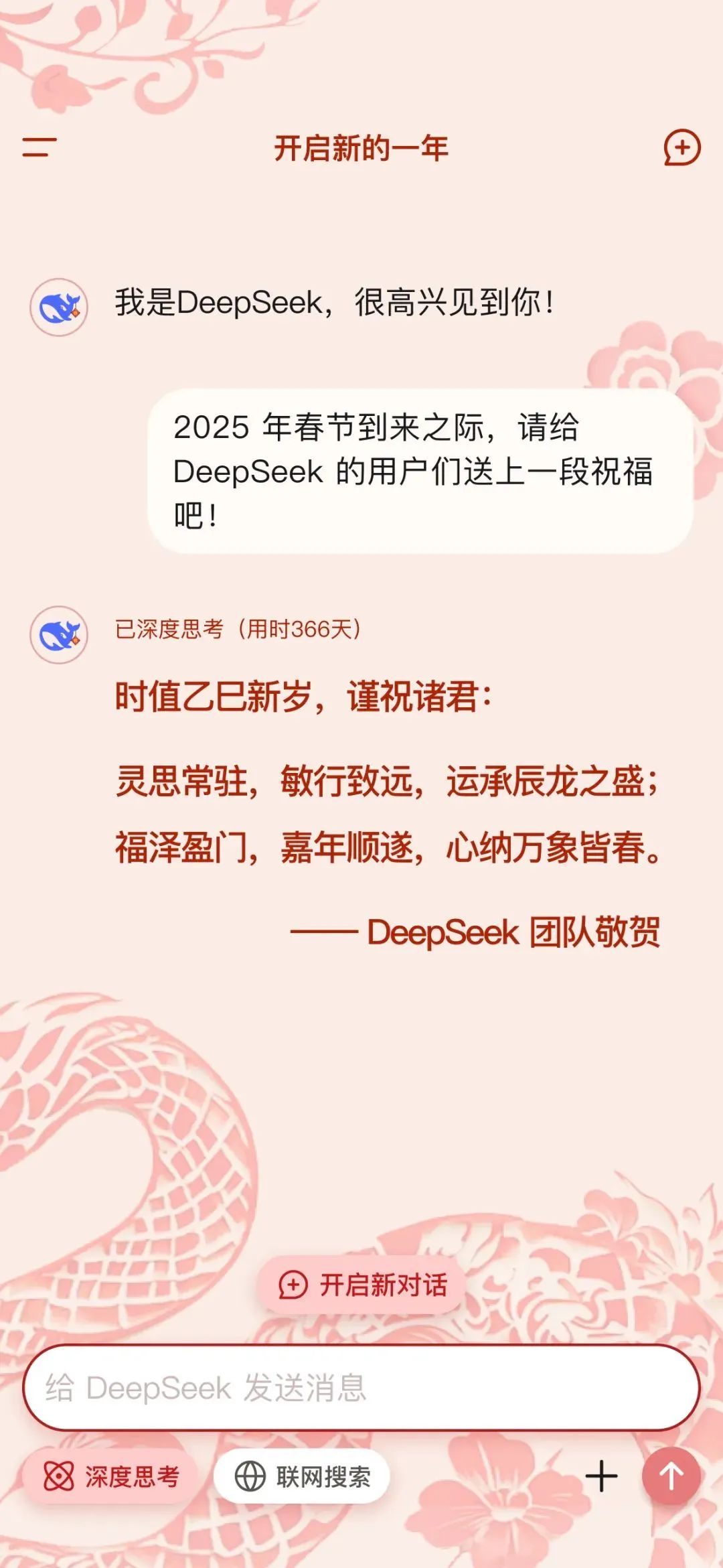
1月27日傍晚DeepSeek最新发布的乙巳新年春节AI贺词


那么,DeepSeek究竟用了什么魔法呢?
比如,他们对通用的模型推理步骤进行了调整。以往模型在提升推理能力时通常依赖于“监督微调”这个环节。这个环节可以简单类比为人类的填鸭式教育,就是让大模型反复做题,学习人类的推理方式。
而DeepSeek-R1在训练过程中直接跳过了这个环节,进入了“强化学习”阶段,探索大模型在没有任何监督数据的情况下,通过纯强化学习进行自我进化。他们要求大模型必须要把思考过程写出来,通过“奖励”引导这个“学生”找到最佳方案。
经历了无数次训练后,大模型这个学生迎来了“Aha moment”(顿悟时刻)。
这个“顿悟”外加其他工程上的优化,DeepSeek证明了疯狂堆积算力、数据的“大力出奇迹”不是通往AGI的唯一路径。
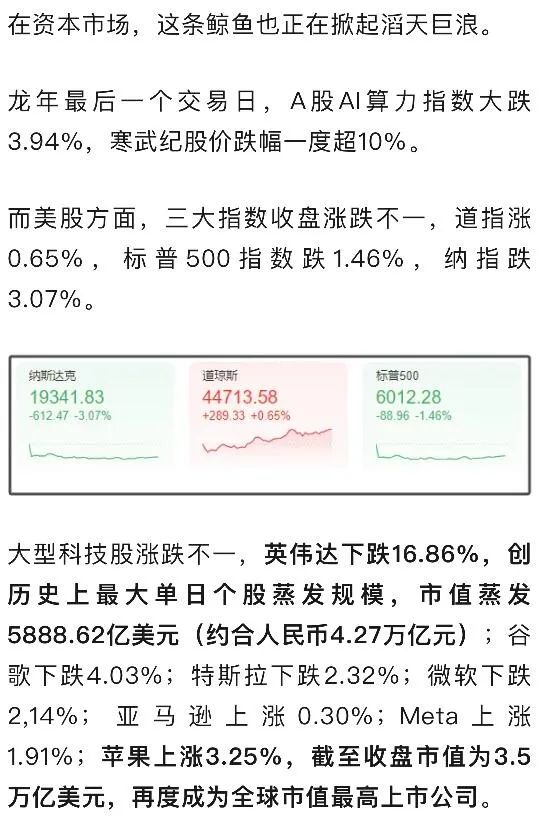
当优雅的算法能够降低对算力的依赖,目前全球的算力是否存在过剩,未来市场对算力的需求是否需要修正?这是近期动摇全球资本市场对科技企业的估值,出现动荡的根本。
最早的AI尝试用在了炒股上
在官方公众号上,DeepSeek对自己的介绍是,投身于探索AGI的本质,不做中庸的事,带着好奇心,用最长期的眼光去回答最大的问题。
在这次一鸣惊人前,很多人在国产的大模型江湖没听说过DeepSeek的名号。一定程度上缘于他们至今没有融过资,更别说接到任何一个巨头的“橄榄枝”。但这并不妨碍他们可能是“国内拥有最多高性能GPU的公司”。
这个底子,是他们做量化投资打下的。在轰炸AI圈之前,DeepSeek及背后的幻方量化是金融江湖成名已久的高手。
低调的创始人梁文锋是80后,出生在广东的一个五线城市,父亲是一名小学老师。他毕业于浙江大学,主修软件工程,人工智能方向。有同事评价梁文锋:完全不像一个老板,而更像一个极客。因为作为老板,他本人每天都在写代码、跑代码,学习能力惊人。
2016年,幻方量化首次上线运行AI策略。2018年,确立了要成为一家AI科技公司。2023年7月,梁文锋在杭州创立深度求索DeepSeek。
在团队配置上,DeepSeek只有139名研发人员,差不多是OpenAI的五分之一。其中,算法、推理框架、多模态等研发工程师以及深度学习方面的研究人员共有约70人。
梁文锋曾透露,DeepSeek并没有什么高深莫测的奇才,都是一些Top高校的应届毕业生,没毕业的博四、博五实习生,还有一些毕业才几年的年轻人,“V2模型没有海外回来的人,都是本土的。前50名顶尖人才可能不在中国,但也许我们能自己打造这样的人”。
无论是在技术还是人才上,梁文锋似乎坚定地看好中国走出自己的模式,从而扮演科技变革引领者的角色。
