
Voyager世界模型的发布为多个行业带来颠覆性变革。在VR/AR领域,它能从单张图片生成一致的3D点云,大幅降低开发成本;在游戏开发中,自动化3D场景生成能力显著提高效率;影视制作方面,相机可控视频生成解放了创作自由度;建筑规划领域可快速将设计转为可探索的3D场景;教育培训则能提供沉浸式学习体验。
在人工智能和计算机视觉这个圈子里,3D场景生成一直是个公认的硬骨头。
虚拟现实 (VR)、增强现实 (AR)、游戏开发这些热门领域,哪个不嗷嗷待哺,等着高质量、能互动的3D场景投喂?需求一天比一天大,但技术瓶颈却始终卡在那里。
腾讯混元团队甩出了一张王牌——混元世界模型-Voyager(HunyuanWorld-Voyager)。号称业界首个支持原生3D重建的超长漫游世界模型,听上去就是要给3D场景生成领域来一次彻底的“改朝换代”。

咱们先聊聊,这事儿为什么这么难?
一直以来,搞3D场景生成的技术路线都挺纠结的。一条路是纯搞视频生成,优点是画面能连续动起来,给你一种沉浸感。但缺点也致命,你看的只是个“影像”,没法真正跟场景互动。想在里面搞个物理仿真或者VR体验?那基本没戏,因为它压根没有真实的3D结构。
另一条路就头铁一点,直接上手生成3D世界。这条路听起来很美好,空间结构一致性强,后续应用拓展性也好。可问题是,高质量的3D训练数据去哪找?又贵又少。而且3D表征那巨大的内存占用,让模型很难泛化到更多样、更宏大的场景里去。两条路,似乎都有点走不通。
混元世界模型-Voyager打破了传统视频生成在空间一致性和探索范围上的天花板,不仅能生成超长距离、全局都对得上的漫游场景,最牛的是,它还能把生成的视频直接导出成3D格式。这一下,就给虚拟现实、物理仿真、游戏开发这些领域送去了最需要的高保真3D场景漫游能力。可以说,Voyager的出现,正式宣告3D场景生成技术进入了下一个时代。
用腾讯混元团队自己的话说,Voyager是混元世界模型1.0的官方扩展。要知道,距离他们发布HunyuanWorld 1.0 Lite版才过了短短两周。这种迭代速度,只能说腾讯在AI领域的研发实力和投入确实有点“恐怖”。
所以,这玩意儿到底是怎么做到的?
混元世界模型-Voyager的背后,是两个“神仙打架”级别的核心组件在协同工作。正是它们的设计,才让长距离、世界一致的视频生成和3D重建从理想照进了现实。
第一个组件叫“世界一致的视频扩散”(World-Consistent Video Diffusion)。你可以把它理解成一个既懂艺术又懂物理的“导演”。传统的视频生成模型,大多是“文艺青年”,只管画面好不好看(生成RGB视频),完全不管物理世界的深度信息。
但Voyager这位“导演”不一样,它在生成视频的时候,创新性地把场景深度预测也给加了进来,相当于同时搞定了视频生成和3D建模两件事。它能根据你给的初始画面和指定的相机移动轨迹,合成出可以自由控制视角、空间上完全连贯的RGB-D视频。这个“D”就是深度(Depth)的意思,意味着视频的每一帧都自带了3D点云信息。

这一招的厉害之处在于:
首先,它是多模态联合生成,RGB视频和深度视频同步产出,而且保证精确对齐,直接省去了后期处理的麻烦,数据质量还高。
其次,它通过一个基于现有世界观测的条件生成机制,确保你生成的视频不管拉多长,从头到尾在视觉上和几何结构上都是统一的,不会出现走着走着墙歪了、桌子没了的诡异情况。
最后,它还是端到端生成,不像老办法那样需要COLMAP这类额外的3D重建工具来“打补丁”,天生就保证了跨帧的一致性。
第二个组件叫“长距离世界探索”(Long-Range World Exploration)。如果说第一个组件是“导演”,那这个组件就是个拥有无限精力的“勘探队”。它解决的是传统模型跑不远、跑着跑着就迷路的问题。
它的核心法宝是一个高效的“世界缓存”机制。具体来说,它会先用混元世界模型1.0生成一个初始的3D点云作为“基地”,然后把这个“基地”的信息投影到你想要去的新视角,给扩散模型当“导航”。
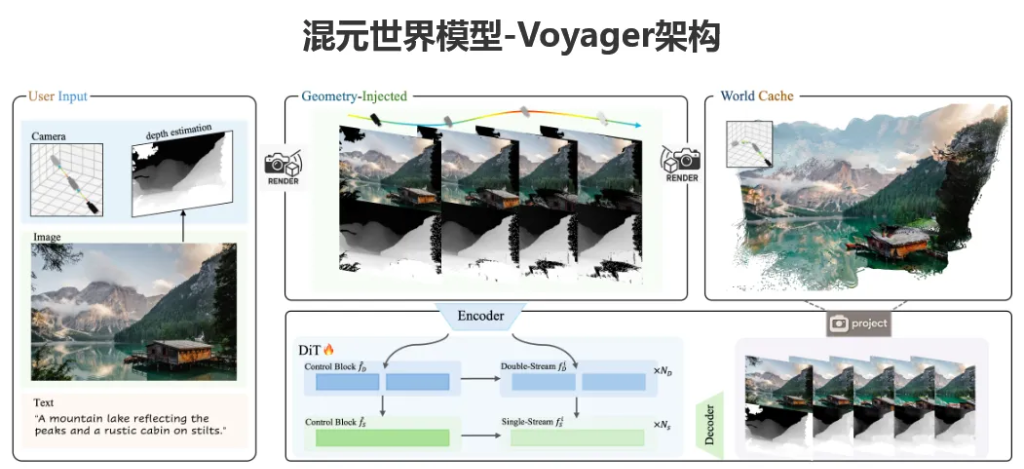
为了应对越来越大的场景,这个“勘探队”还学会了“点云剔除”技术,聪明地管理和优化海量的点云数据,大大提升了计算效率。更妙的是,它采用了一种自回归的推理方式,简单说就是“边走边看边记”。新生成的视频帧会实时更新那个“世界缓存”,形成一个闭环系统。
这样一来,无论你的相机轨迹多么风骚,它都能保持几何上的一致性,不仅把漫游范围拓宽了,还能反过来给混元世界模型1.0补充新的视角内容,让整体生成质量更上一层楼。再加上一个叫“上下文感知的一致性技术”来保证视频采样丝滑流畅,最终给你的就是电影级的沉浸式体验。
把这两个组件合在一起,Voyager就能实现从一张静态图出发,生成一个全局一致的3D点云世界,然后让你拿着“虚拟摄像机”,想怎么逛就怎么逛。逛的同时,它还把带精确深度信息的RGB视频一起生成了,高质量的3D重建简直是信手拈来。
用“暴力美学”喂出来的大模型
要训练出Voyager这么一个“怪物”,得喂给它多少“精神食粮”?他们搭建了一套堪称“数据永动机”的引擎——一个全自动的视频重建流水线。这套系统能把任何输入的视频,自动估算出相机位姿和真实的度量深度。这意味着什么?意味着他们彻底摆脱了昂贵又耗时的人工标注,可以规模化、多样化地生产训练数据。
这个数据引擎的工作流程大概是这样的:
先把视频扔进去进行预处理,挑出质量好的帧。然后,用上了SLAM (同步定位与地图构建) 和捆绑调整算法,自动算出每一帧的相机位置和朝向,这是训练相机可控模型的关键。
接着,用深度估计模型预测出每一帧画面的深度信息,和RGB图像配对,就成了Voyager最爱吃的“RGB-D套餐”。最后,系统还会自动检查对齐和验证数据质量,把不合格的样本踢出去。
靠着这套自动化流水线,团队整合了真实世界里拍的视频和用虚幻引擎渲染的视频,硬是攒出了一个包含超过10万个视频片段的超大规模数据集。这个数据集不仅量大管饱,而且来源多样,涵盖了各种场景和风格,并且每一份数据都自带了相机位姿和度量深度这些宝贵的“标签”。
正是这个高质量、多样化的大数据集,才把Voyager“喂”得如此强大。
在检验成果的时候,研究团队用了一个叫RealEstate10K的公开数据集来当“考官”。这个数据集来头不小,是从YouTube上大约1万个视频里扒出来的,包含了大约1000万帧图像和对应的相机运动轨迹,是评估视频生成和3D重建任务的黄金标准。Voyager的很多关键性能,就是在这个数据集上跑出来的。
光说不练假把式
了测试Voyager到底有多能打,腾讯混元团队从视频生成质量、三维场景重建能力和世界生成能力三个维度,对它进行了一次全方位的“大考”。
首先是视频生成质量。研究团队把Voyager和四种主流的开源相机可控视频生成方法放在一起同台竞技。他们在RealEstate10K测试集里随机挑了150个视频片段,用PSNR、SSIM和LPIPS这三个业界公认的指标来打分,分别衡量生成画面和真实画面的感知相似性与结构一致性。

结果怎么样?看表就知道了。
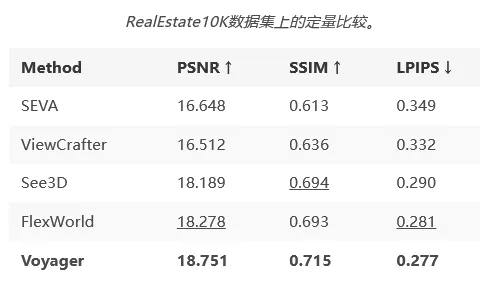
Voyager在所有指标上都实现了全面领先,可以说是毫无悬念地拿下了第一。PSNR指标达到了18.751,比第二名高了将近0.5;SSIM指标是0.715,同样力压群雄;LPIPS指标则是越低越好,Voyager的0.277是全场最低分,说明它生成的内容在人眼看来和真实的视频最像。
再看看具体的生成效果对比,差距就更明显了。尤其是在最后一组例子里,只有Voyager成功地保留了输入图像中产品的细节特征。反观其他几个方法,要么就产生了明显的瑕疵,要么就像第一个例子里那样,当相机运动幅度一大,直接就“崩了”,生成了完全不合理的结果。

接下来是更硬核的场景生成质量评估。因为对手们都只能生成RGB帧,研究团队还挺“贴心”地先用一个叫VGGT的工具帮它们估计相机参数,再用它们生成的视频来初始化点云。
而Voyager这边就轻松多了,因为它直接生成RGB-D内容,根本不需要任何中间处理,就能直接拿去做高质量的3D Gaussian Splatting (3DGS) 重建。
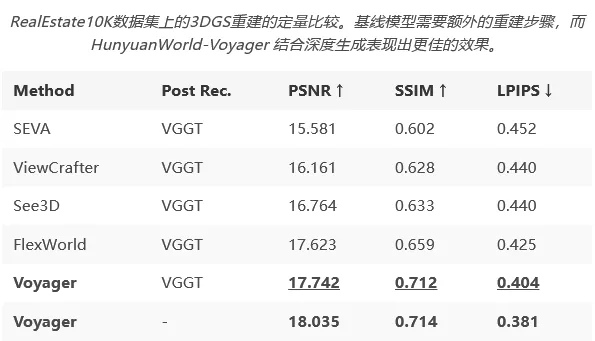
从表格数据可以看到,即便是在对手们都用了VGGT“外挂”的情况下,Voyager的重建结果依然是最好的,这说明它生成的视频在几何一致性上确实更胜一筹。而当Voyager使用自己生成的深度信息来初始化点云时(也就是完全不用后处理),效果还能更上一层楼,这直接证明了它那个深度生成模块的强大之处。
从定性结果看,比如在最后一组的吊灯例子里,Voyager很好地保留了吊灯的复杂细节,而其他方法连基本形状都重建不出来,高下立判。
最后,是世界生成能力的终极考验。团队把Voyager拉到了WorldScore这个静态基准上进行评测。这个基准由斯坦福大学李飞飞团队提出,是专门用来统一评估世界生成模型的,含金量极高。
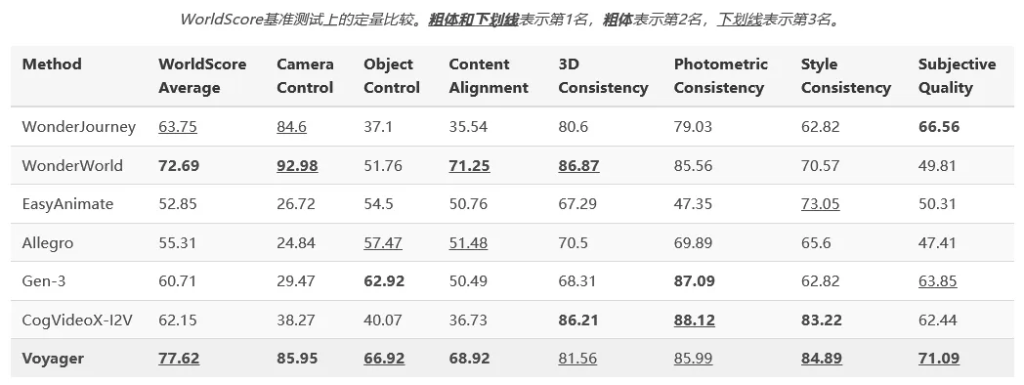
结果再次震惊全场。Voyager以77.62的综合得分雄踞榜首,把其他模型远远甩在身后。在各项细分指标里,它在物体控制、内容对齐、风格一致性和主观质量四个方面都是第一,相机控制排第二,3D一致性和光度一致性也表现优异。
这充分说明,Voyager在相机运动控制和空间一致性上,已经具备了和顶级3D方法一较高下的实力。特别是在主观质量评价上拿到最高分,再次验证了它生成视频的视觉真实感。
所以,这将如何改变我们的世界?
Voyager的发布,绝不仅仅是一次技术参数的刷新,它真正开启的是一片广阔的应用蓝海。作为第一个能打通“超长漫游”和“原生3D”的的世界模型,它给好几个行业都带来了颠覆性的想象空间。
在虚拟现实 (VR) 和增强现实 (AR) 领域,Voyager简直就是天降甘霖。过去,VR/AR应用里的3D场景基本靠“堆人力”,建模师们苦不堪言,不仅耗时耗力,还很难搞定大规模场景的实时生成。现在Voyager来了,
从一张图就能生成一个世界一致的3D点云,还支持你自定义路径去探索。这意味着开发者可以光速生成大规模的3D场景,开发周期和成本双双打折。而且,它生成的RGB-D视频可以直接用于渲染,效率直接拉满。
游戏开发行业同样迎来了福音。传统游戏开发里,3D场景建模是个重活、苦活。而Voyager的自动化3D场景生成能力,就是给游戏开发者送上的一把“神器”。无论是做游戏原型的快速开发,还是像开放世界游戏那样需要超大地图的场景生成,Voyager都能大大提高效率。它甚至能根据用户的输入实时生成动态内容,给游戏玩法带来了更多可能。
对于影视制作和动画领域,Voyager的相机可控视频生成能力,让创作变得更自由。过去那些复杂的镜头运动,现在可能只需要输入一张图和一条相机路径就能搞定。这不仅是效率的提升,更是创作自由度的解放。
在建筑与城市规划领域,Voyager则是一个强大的可视化工具。设计师们可以快速地将他们的设计草图或照片,变成可供自由探索的详细3D场景,与客户和同事的沟通效率将发生质的飞跃。
甚至在教育与培训领域,Voyager也能大放异彩。想象一下,医学生可以在Voyager生成的精细3D人体器官模型里进行虚拟解剖学习,工科生可以拆解和观察复杂机械的3D结构,这种沉浸式的学习体验,效果远非书本和PPT可比。
混元世界模型-Voyager的发布,漂亮地解决了传统路线上的核心矛盾,为业界树立了一个全新的技术标杆。
腾讯混元团队也表示,Voyager与之前的混元世界模型1.0和1.0 Lite版共同构成了完整的技术体系。
随着它的开源,更多的开发者和研究者将能站在这位“巨人”的肩膀上,去探索和创造更多可能。
