
AI在价值投资中的应用:我的实践
在回答学生关于如何准备投资职业的问题时,巴菲特对他们说:“每天像这样读500页。”他说着指向一堆手册和文件。“知识就是这样积累的,就像复利一样。你们所有人都能做到,但我敢保证,很少有人会去做。”
在《滚雪球》一书中,Alice Schroeder 也记录过:…人们看到他(巴菲特)从早到晚埋头翻阅手册,充实他的知识文件柜。“我一页一页地翻阅了《穆迪手册》。工业、交通、银行和金融类的《穆迪手册》共有一万页——我看了两遍。我确实浏览了每一家公司——虽然有些只是粗略地看了一眼。”巴菲特说。
投资其实就是这样是一个金字塔形状,不断信息收集、提炼的过程。最底层,是各种如财报、新闻、会议纪要之类的原始的资料,然后从这些原始数据中提炼出各个公司生意和财务框架。等脑海中框架逐渐完善丰富后,偶尔能产生几条投资洞见。最顶层,只有买和卖这样两个判断。
在实践这门学问的过程中,我之前常被这两个问题困扰:
1. 收集的信息零散。看完很多pdf 随手一存,里面的做的标注时间一长也忘了。复用的情况不高。
2. 花了很多时间在基本信息的收集和整理上。这是由于绝大部分商业信息还是在用自然语言发布和描述。各个公司的格式、关键运营指标、名词定义并不相同。
AI大语言模型和RAG 技术的出现,对于解决这两个问题起到了很大的帮助。具体说,它的技术突破在于可以从非结构化的原始文件中比较准确有效地提取数据出来。
利用这个技术,我做了Know2.co 复知投研这个工具。它在没有改变我工作流程的情况下,大幅提高了我研究效率。现在我的研究流程如下:
第一步:
我看完注释完的PDF原始资料,或自己的工作草稿,无论是Word,或Excel, 还是直接保存到本地的OneDrive目录下。Know2会将OneDrive的文件自动同步到Know2我的私人文件柜。
每家被研究的公司也有一个Sharepoint公共文件柜。一些常规的公司定期报告会由网页爬虫自动下载到公司的公共文件柜中。有几个小伙伴一起研究的公司原始资料也可以上传到那共享。
文件柜中的资料会被自动地分页,向量化索引。我高亮和注释的部分也会被单独提取出来存成文件。
第二步:
我现在就可以在Know2的网页版报告编辑器上,或者在Word, Excel的Know2插件中,用我的私有数据+AI进行查询、数据提炼。
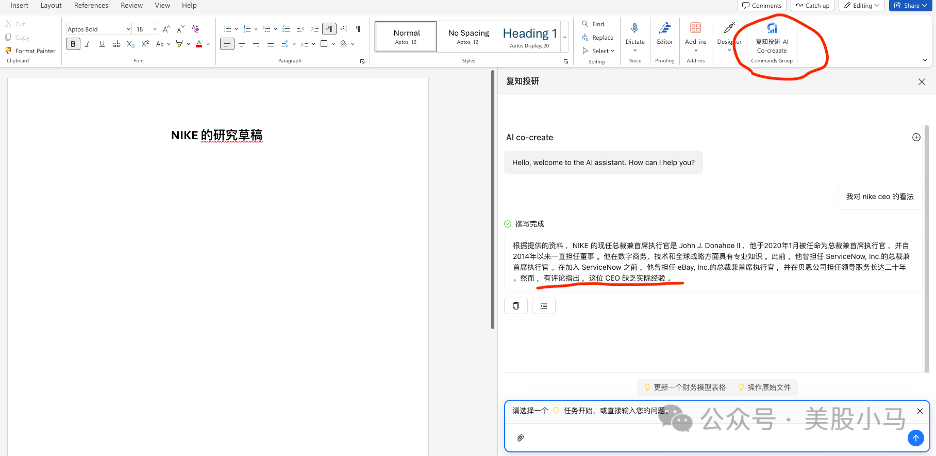
比如下图,我看完NIKE在写一个总结,NIKE CEO的情况加自己的注释可以被轻松找出来。
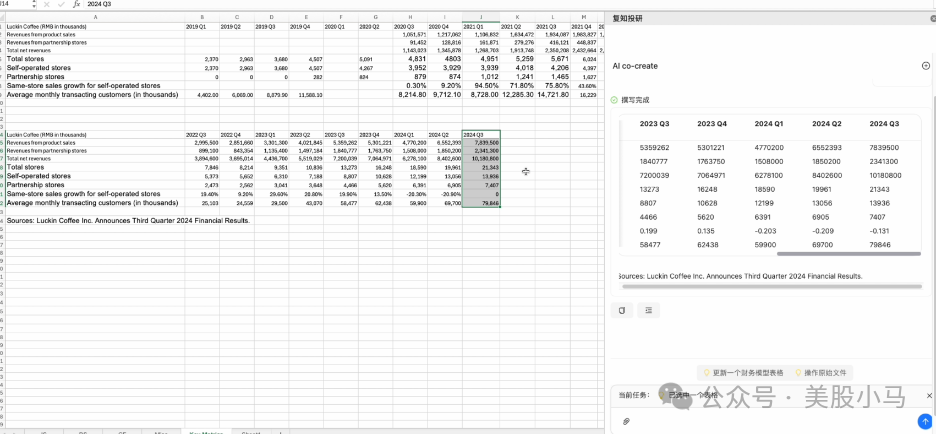
再比如,对一家已经在跟踪的公司,更新一下新的季度数据变得很快。
更重要的是,我现在可以做一些公司基础信息的研究模版,将基本公司信息和数据的搜索整理任何交给AI,而我则只需负责这些信息的核对、和用更多时间进行单项课题深入研究。
按照这个思路,我做了一些公司的基本信息模版。全部是基于年报信息+AI辅助。这就像用AI做了一个自己版本的Value Line或穆迪手册,方便我快速初筛公司和建立感兴趣公司的研究基础框架。欢迎大家看一看,给我些反馈。
中海油 vs. 西方石油OXY
https://know2.co/company/38
https://know2.co/company/11
农夫山泉 vs. 华润饮料vs. 中国旺旺
https://know2.co/company/29
https://know2.co/company/77
https://know2.co/company/76
瑞幸咖啡 vs. 星巴克
https://know2.co/company/75
https://know2.co/company/14
免责声明:上述内容仅代表发帖人个人观点,不构成本平台的任何投资建议。
