
99%的人不知道:小龙虾(Openclaw) 在为你打工?实际上是你在给小龙虾打工!

小龙虾OpenClaw系列,加入AI社群请后台私信:社群
防失联,和谐,后台私信工作邮箱!
如何利用OpenClaw 打造自己的量化工作站01
如何利用OpenClaw 打造自己的量化工作站02 |搭建量化中控台
99%的人不知道,如何用OpenClaw(小龙虾)搭建上市公司财报分析系统 01
十大OpenClaw 搞量化最高效方法/思路
99%的人用小龙虾(OpenClaw)都用错了:最常见的10个致命错误
“小龙虾”究竟是技术革命,还是又一场集体焦虑?
我对小龙虾和AI现状的几点看法
自从小龙虾爆火之后,很多人开始使用小龙虾,一开始兴冲冲以为终于可以指挥千军万马创建黑客帝国纵享一人企业百个llm模型搬砖的丝滑,结果发现跑了最简单的删除邮件任务之后tokenburn爆表。
发现原来小龙虾一点都不便宜!
牛逼哄哄浏览器打开自行处理任务,结果发现token买单的时候500刀!
你才发现,你以为小龙虾在给你打工,
其实是你在给小龙虾打工!
今天我们来重点聊聊小龙虾是如何烧钱的?
如何控制小龙虾的成本,真正让AI做你的24小时打工仔!
这是真正的烧钱结构:从 Heartbeat 到 Skill,一份系统级成本止损指南
很多人第一次跑起 OpenClaw 的时候,注意力都放在同一批问题上:
它能不能连上模型?工具能不能调?浏览器能不能动?
很少有人在第一天认真问另一个问题:
这个系统到底在哪些地方、以什么频率、用什么机制在花我的钱。
结果就是,系统看起来很顺,聊天很丝滑,几天后回头看账单——人直接清醒。
不是因为 OpenClaw 有什么阴谋。是因为他们从一开始就没把它当成一个带持续运行成本的调度控制平面来看。
你以为你在发消息而已?后台还在跑一堆进程!
OpenClaw 官方文档对架构写得很清楚:整个小龙虾系统围绕一个单一 Gateway 进程设计。这个进程会持续维护:
- 会话状态(Session State)
:sessions.json、JSONL transcript、上下文重建与压缩
- 工具注册与调用链
:每次模型响应后,系统根据工具调用结果决定是否再次进入模型
- 系统提示重建
:每次运行时重建,包含工具列表、skills 元数据、工作区位置、运行时信息
- Channels 路由层
:多频道并发,每个 channel 独立维护历史、模型配置、工具访问权限
你看到的是一行输入。系统实际处理的是一整条有状态的调用链。
这是理解所有成本问题的起点。
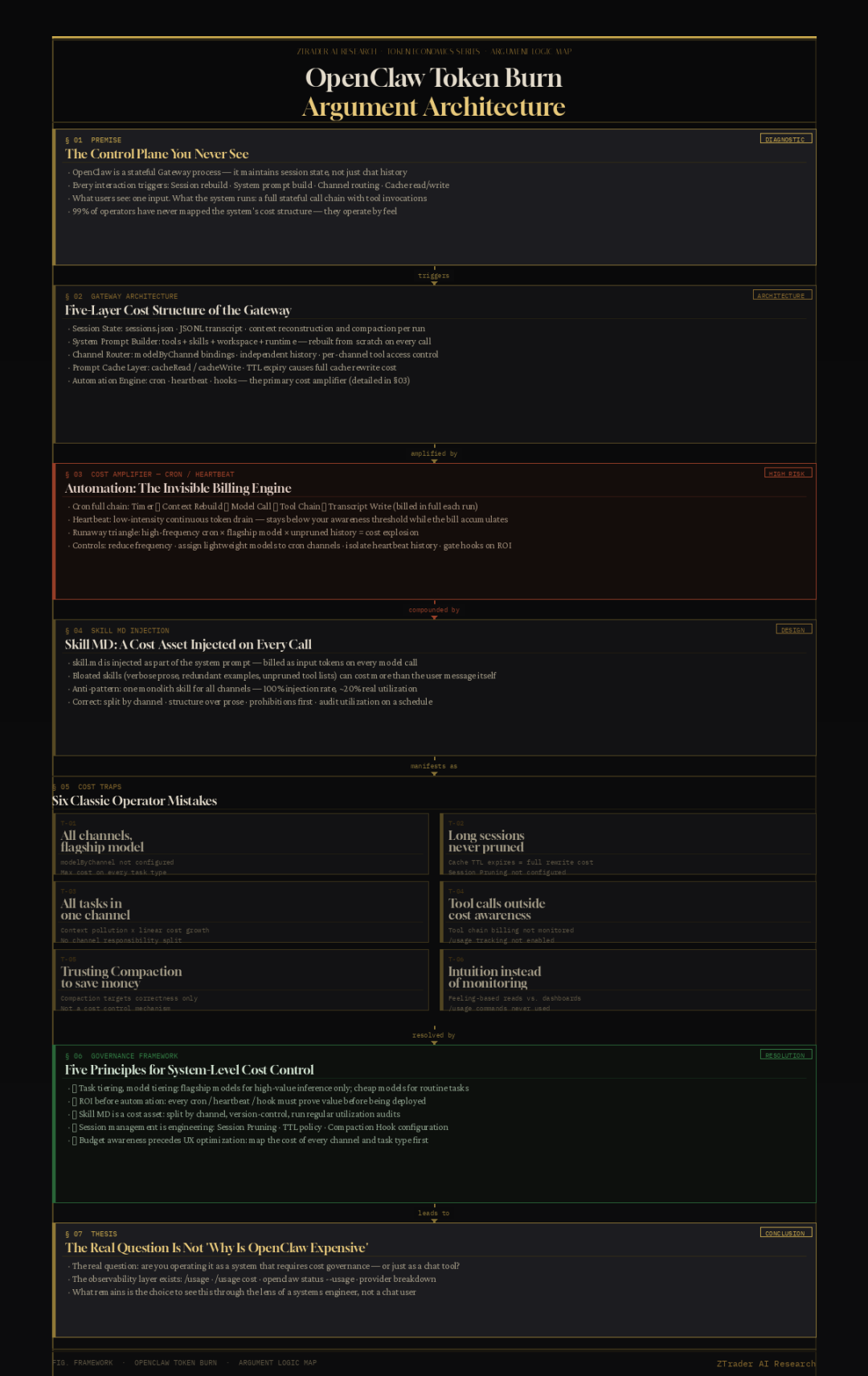
最容易被忽视的成本放大器:Cronjob 与 Heartbeat 机制
这是大多数文章根本不写、大多数用户第一次翻文档也跳过的部分。
但这里才是账单失控最常见的根源。
OpenClaw 支持 automation层,允许你挂载 cron 任务和 heartbeat 触发。表面上看,这是"自动化效率神器"。实际上,它是一个没有天花板的成本放大器,除非你非常清楚自己在做什么。
Cronjob 的实际行为
Cron 任务在 OpenClaw 里不只是"定时发一条消息"。它的完整链路是:
- Cron 触发
→ 系统唤醒对应 channel
- 上下文重建
→ Gateway 重新拼装系统提示 + 历史 + 工具列表(即使这个 channel 已经几小时没动过)
- 模型调用
→ 走你配置的模型,完整计费
- 工具调用链
→ 如果任务涉及工具(浏览器、文件、API),每次工具调用都可能触发额外模型轮次
- Transcript 写入
→ 结果写回 JSONL,更新 session 状态
一个"轻量日报 cron",底层走的链路可能是:系统提示重建 + 历史打包 + 模型调用 + 2-3 次工具调用 + 结果结构化 + 写回状态。
如果你的日报 cron 每小时跑一次,你的模型是 claude-opus 或 gpt-4o,你的 channel 历史又没有修剪——这条"自动化"每天在烧多少你根本不知道。
Heartbeat 的实际行为
Heartbeat 机制比 cron 更隐蔽。它是一种保活轮询:系统按照你配置的间隔向 channel 或 agent 发送存活信号,确认状态、检查任务队列、触发挂起动作。
Heartbeat 本身的 payload 可能很小。但问题不在 payload,在于:
- 每次 heartbeat 都可能触发上下文重建
(如果 channel 配置了 system prompt 刷新)
- 挂在 heartbeat 上的 hook 可能触发额外模型调用
- 高频 heartbeat + 复杂 channel = 持续的低烈度 token burn,根本不会触发你的感知阈值
你以为什么都没发生,账单在安静地涨。
控制 Cronjob/Heartbeat Token Burn 的正确方法
1. 降频是第一原则
每降一档频率,成本减少的不只是倍数,还有上下文重建次数。日报从每小时降到每天,不是省 24 倍,是省了 24 次上下文重建 + 24 次完整链路。
2. 给 Cron Channel 单独配置轻量模型
channels.modelByChannel允许你把特定 channel 绑定到不同模型。日报、通知、状态轮询这类任务,没有理由走旗舰模型。用 haiku、mini、flash 这类低成本模型处理,主链路强模型只在需要推理的节点介入。
3. Heartbeat Channel 要做历史隔离
不要让 heartbeat channel 积累对话历史。它的目的是保活和状态同步,不是对话。把它的 history 设置为最小窗口,每次轮询后做清理。
4. 对 Cron 任务强制 session pruning
OpenClaw 的 session pruning 设计出来就是为了解决这个问题:在缓存 TTL 过期后修剪会话,避免长对话在重新缓存时把账单抬起来。Cron channel 尤其需要这个——因为它的历史会在每次触发时被打包重送,你不剪,它就一直胖下去。
5. Hook 挂载前先问 ROI
每个 pre-compaction hook、post-run hook、automation hook 都是一个潜在的额外调用节点。在你挂上去之前,问自己:这个 hook 的输出值,是否覆盖它每次触发的模型成本?如果答案不确定,先不挂。
Skill MD 的成本维度:99%用户完全没想到这层
OpenClaw 的 Skill 系统允许你通过 markdown 文件定义 agent 的能力边界、行为规则和工具使用指引。大多数人把 skill.md 当成"功能增强工具"。
它实际上也是系统提示的一部分,每次运行都会被注入。
这意味着:
Skill MD 的膨胀 = 系统提示成本的膨胀
如果你的 skill.md 写得很啰嗦——大量解释性文字、重复的规则、冗余的示例、没有剪枝的工具描述——它在每次模型调用时都会作为 input token 计费。
这意味着,一个写得糟糕的 skill.md 可能比你的用户输入还贵。
正确设计 Skill MD 的成本意识原则
原则 1:能用结构就不用散文
Skill MD 不是给人读的教程,是给模型读的指令集。散文解释 = token 浪费。改用:
## Behavior Rules- Output format: JSON only, no prose
- Tool use: only call tools listed in `allowed_tools`
- On ambiguity: ask one clarifying question, not multiple
原则 2:按 channel 分 skill,不要写一个万能 skill
一个覆盖所有场景的 skill.md 会变成一个胖怪兽,每个 channel 都注入它,但大多数 channel 只用其中 20% 的规则。
按职责拆分:research_skill.md、report_skill.md、notify_skill.md。每个 channel 只注入它真正需要的 skill 文件。
原则 3:示例要精,不要多
Few-shot 示例有价值,但每个示例都是 token 成本。两个精准示例比六个泛化示例更便宜、也更有效。
原则 4:定期 audit skill MD 的实际利用率
开 /usage tokens或 /usage full,对比有无 skill 注入时的 input token 差值。如果差值很大但任务质量没有显著提升,这个 skill 需要瘦身。
原则 5:把禁令写在最前面
模型读 prompt 是有注意力衰减的。把最重要的行为约束、格式要求、工具限制放在 skill.md 开头,而不是藏在中间。这样可以用更少的规则字数达到更强的控制效果。
其他六个经典坑
坑 1:强模型覆盖所有 channel研究频道用强模型可以理解,日报、整理、通知频道也全用旗舰模型,是在用最贵的汽油给全楼供暖。channels.modelByChannel就是为这个设计的,不用是真浪费。
坑 2:长会话不修剪Prompt caching 有 TTL。TTL 过期后,如果你不做 session pruning,下一次请求会重新写入大块缓存,cacheWrite 成本重新放大。不是"聊了就省钱",是"管好了才省钱"。
坑 3:一个 channel 塞所有任务上下文污染是线性成本的乘数。研究、调试、内容、测试全塞同一条历史链,后面每次请求都在喂一个越来越胖的 transcript。按职责分 channel,是基本架构卫生。
坑 4:不知道工具调用也计费"主对话回复"只是冰山一角。工具调用、自动化路径、历史重建、多轮工具链——每个节点都计入 provider 成本。不看 usage tracking,天然低估系统调用密度。
坑 5:误以为 compaction 会自动省钱Compaction 和 transcript hygiene 的目标是正确性,不是成本控制。它们最多把上下文修正得能跑,真正决定花多少钱的是你的会话设计、模型选择、工具策略。
坑 6:用感觉代替监控/usage off|tokens|full、/usage cost、openclaw status --usage这些入口都在。不开,就只能靠情绪判断。系统工程里最贵的坏**惯,是用感觉代替仪表盘。
真正的成本框架:五条原则
原则 1:
任务分层,模型分级强模型只做复杂推理、高价值判断。轻量任务走轻量模型。这不是在凑合,是在做正确的资源调度。
原则 2:
Automation 的 ROI 先于 Automation 本身每个 cron、每个 heartbeat、每个 hook 都是成本节点。在你挂上去之前,先证明它的输出值覆盖触发成本。没有 ROI 的自动化,是自动烧钱机器。
原则 3:
Skill MD 是成本资产,要当代码管理版本化、定期 audit、按 channel 拆分。臃肿的 skill 和臃肿的代码一样有技术债——只不过技术债不会每次调用都扣钱,skill 会。
原则 4:
长会话管理是工程任务,不是懒得理的事Session pruning、prompt caching TTL 管理、compaction hook——这些机制都是现成的。不用,是主动放弃成本控制权。
原则 5:
预算感知先于体验优化在你没有建立"每个 channel、每类任务、每条链路大概烧多少"的基本感知之前,任何体验优化都是在一栋不知道水电费的房子里装修。先把仪表盘装到脑子里。
最后,
真正的问题不是"OpenClaw 怎么这么容易烧钱"。
真正的问题是:你是否把它当成一个需要成本的系统来优化成本。
大多数人以为自己在发消息。 实际上他们在驱动一个带会话状态、上下文重建、工具调用链、cron 触发、heartbeat 轮询、skill 注入、缓存写读、多 channel 路由的控制平面。
每一层都在计费。每一层都有优化空间。
不出问题,是因为还没到那个规模。 出了问题,是因为从一开始就没建立成本优化模式,只有具备了优化机制,
打工仔才能24小时用最低成本给你丝滑搬砖
免责声明:上述内容仅代表发帖人个人观点,不构成本平台的任何投资建议。
