
通用GPU的护城河,会不会被定制ASIC掏空?
拐点分两层:单位先翻盘,美元还没到
2026.06.25·技术前沿

结论定制ASIC已从“降本边角”走向超大厂默认路线,但真正的杀招不是单芯片,而是设计权流动与推理外流。
定制ASIC,不再是省钱的边角料。
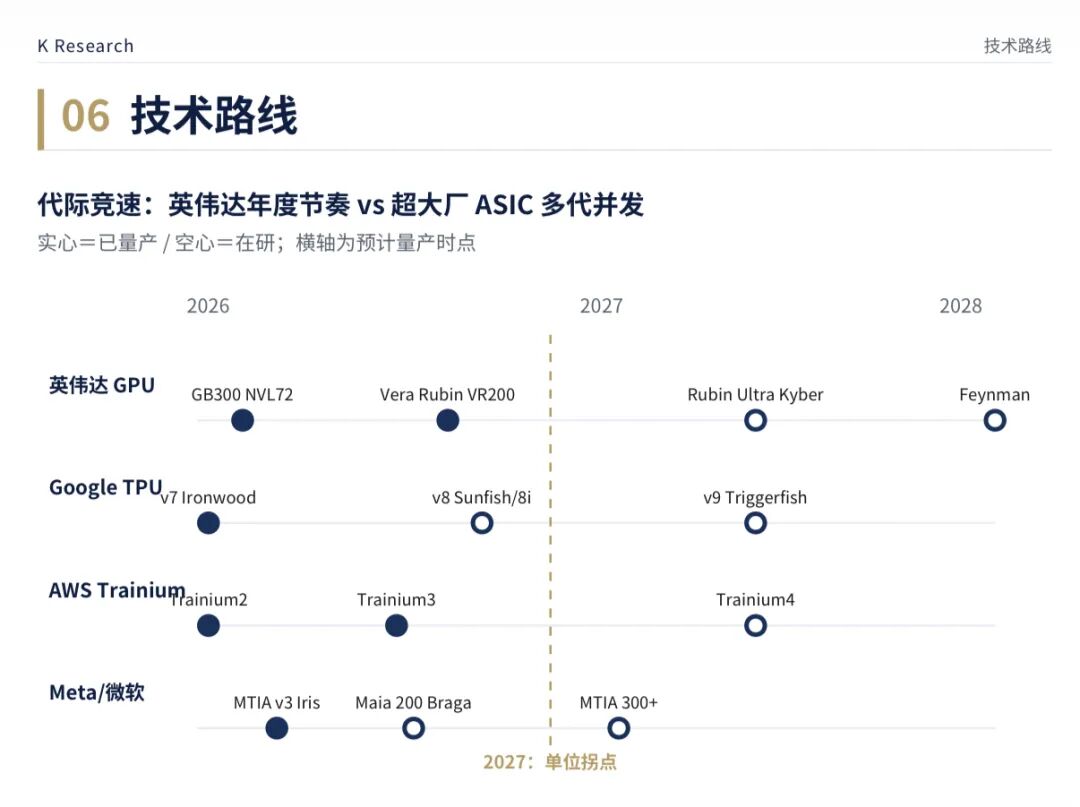
它正从“降本选项”变成超大厂的默认路线,逼着市场重估英伟达的垄断。
OpenAI 宣布自研 10GW 加速器,首 1GW 落在 2027;Anthropic 押注 1M+ 颗 Trainium 与 TPU,几乎全面离开英伟达。

这不是个案。Broadcom 手握 6 家自研 XPU 客户,FY27 的 AI 订单口径已被 Hock Tan 提到“逾 $100B”。
JPMorgan 测算:2027 年全球加速器约 23.3M 颗,ASIC 约 12.5M(53%)首次反超 GPU 约 10.9M(47%)。—— JPMorgan 2026
但拐点要拆两层:单位 2027 翻盘,美元口径未到。Morgan Stanley 看 2028 年 TAM 约 $380B,GPU 仍占约 75%。
真正的杀招,是设计权开始流动。据郭明𫓹,联发科拿下 Google TPU v9 增强版“Triggerfish”,首次主导核心变体。
机制藏在物理里:联发科 336G SerDes 已就绪,Broadcom 的 448G 受 2nm 与铜互连所限,滑到 2028–29。
| SerDes | 联发科 | Broadcom |
| 速率 | 336G 就绪 | 448G 滑期 |
| 量产 | 2027 | 2028–29 |
另一刀是推理外流:Google Ironwood 单芯 TCO 较 GB200 低约 44%,Trainium 便宜约 30–40%,稳定大规模推理正被搬离 GPU。
需求侧也在配合:四大厂 2026 资本开支合计约 $630–725B,约 75% 砸向 AI 基建,足够养活多条自研路线。原创研报已上传。
英伟达不认账。黄仁勋称自研超越 GPU“doesn't make sense”(这事说不通),因为算法还在变,需要 GPU 的灵活性。—— 黄仁勋 2026.02
护城河正从硅迁到网。英伟达用 NVLink Fusion 把对手变供应链,$20亿投 Marvell。下一个验证窗,盯 networking attach 率与毛利率,而非数据中心营收本身。CWW,
免责声明:上述内容仅代表发帖人个人观点,不构成本平台的任何投资建议。
