
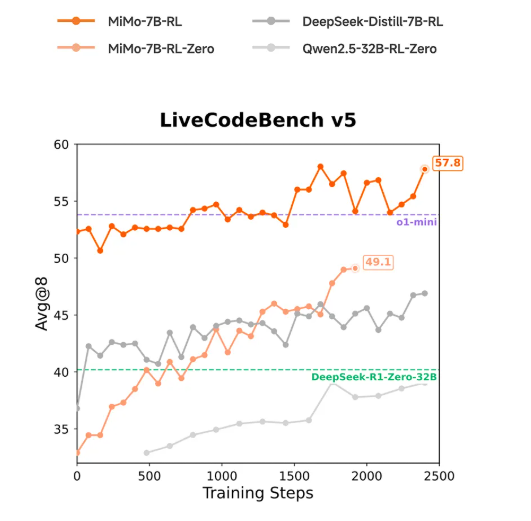
在相同强化学习(RL)训练数据条件下,MiMo-7B在数学和代码领域展现出的强化学习潜力明显领先于业界广泛使用的其他模型,包括DeepSeek-R1-Distill-7B和Qwen2.5-32B等知名强化学习起步模型。
AI竞赛激烈,小米也加入战局!
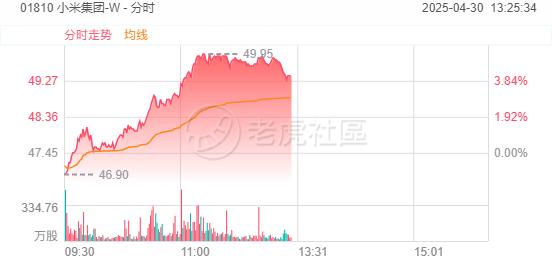
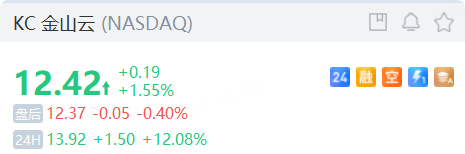
4月30日,小米首个推理大模型开源!概念股强势上扬,金山云飙升逾14%,小米集团-W、金山软件涨逾4%;金山云美股夜盘大涨逾12%
小米推出专注推理能力的开源大模型MiMo,仅用7B参数规模在数学推理和代码竞赛测评中超越OpenAI的闭源模型o1-mini以及阿里32B规模的QwQ。
据小米介绍,Xiaomi MiMo诞生之初探索的核心问题就是激发模型推理潜能,这款模型联动预训练到后训练,全面提升推理能力。
国内外AI竞争日趋白热化,本周阿里前脚发布Qwen 3,马斯克后脚就官宣Grok 3.5。而据此前媒体报道,小米正在建设万卡GPU集群,并引入顶尖AI人才,显示出对大模型领域的全面投入。
性能突破:小参数量实现大能力
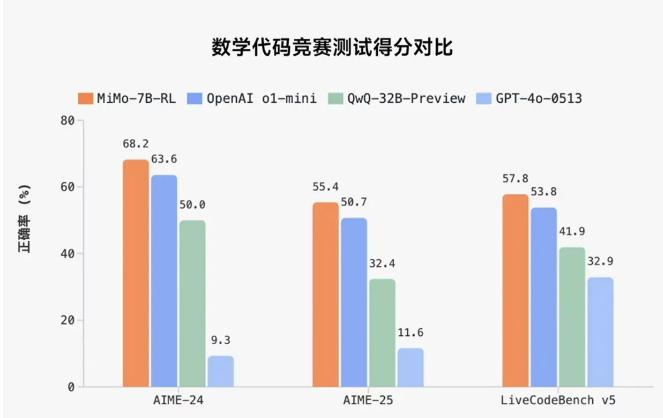
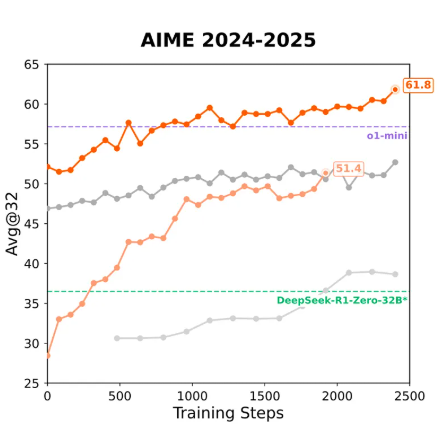
Xiaomi MiMo这款模型最引人注目之处在于,在数学推理(AIME 24-25)和 代码竞赛(LiveCodeBench v5)公开测评集上,MiMo 仅用 7B 的参数规模,超越了 OpenAI 的闭源推理模型 o1-mini 和阿里 Qwen 更大规模的开源推理模型 QwQ-32B-Preview。
更值得注意的是,在相同强化学习$(RL)$训练数据条件下,MiMo-7B在数学和代码领域展现出的强化学习潜力明显领先于业界广泛使用的其他模型,包括DeepSeek-R1-Distill-7B和Qwen2.5-32B等知名强化学习起步模型。
技术关键:预训练与后训练双轮驱动
据小米介绍,MiMo模型的成功并非偶然,而是来自于预训练和后训练两个阶段的多层面创新。
在预训练阶段,小米团队着重挖掘富含推理模式的语料,并合成了约200B tokens的推理数据。训练过程采用三阶段策略,逐步提升训练难度,累计训练了25T tokens,这一训练量在同等规模模型中处于领先水平。

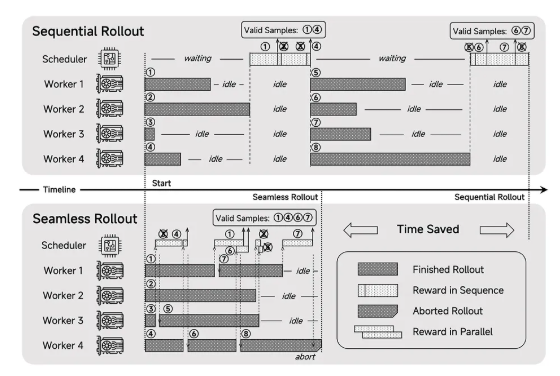
后训练阶段的创新更为关键,小米团队提出了"Test Difficulty Driven Reward"机制,有效解决了困难算法问题中奖励稀疏的问题。同时引入"Easy Data Re-Sampling"策略,显著提升了强化学习训练的稳定性。在框架层面,他们设计了"Seamless Rollout"系统,使得强化学习训练速度提升2.29倍,验证速度提升1.96倍。
技术之外:小米的AI全面投入战略
据界面新闻报道,小米正在搭建自己的GPU万卡级集群,将对AI大模型进行大力投入。一名知情人士透露,该计划已经实施数月之久,小米创始人雷军亲自参与领导。该人士强调:"在AI硬件这件事情上,最核心的是手机而不是眼镜,小米在这个领域不'all in'是不可能的。"
小米的AI人才布局也在加速。12月20日,第一财经报道称DeepSeek开源大模型DeepSeek-V2的关键开发者之一罗福莉将加入小米,或供职于小米AI实验室,领导小米大模型团队。罗福莉是MLA(Multi-head Latent Attention)技术的核心开发者之一,该技术在降低大模型使用成本上发挥了关键作用。