
seeking β day 263,本地部署dpsk✅
欢迎关注公众号:股海彦祖
无操作。我的xhs账号之前都没事,昨晚写的有点敏感,可能被xhs的管理员关注到,顺手就把我账号封了,虽然只有7天吧,但历史文章和评论全部隐藏……🌿
图二这个蝴蝶兰,是我21年5月提蔚来时送的,最近气温回暖,又开花了,旁边还有几个含苞待放的花骨朵。
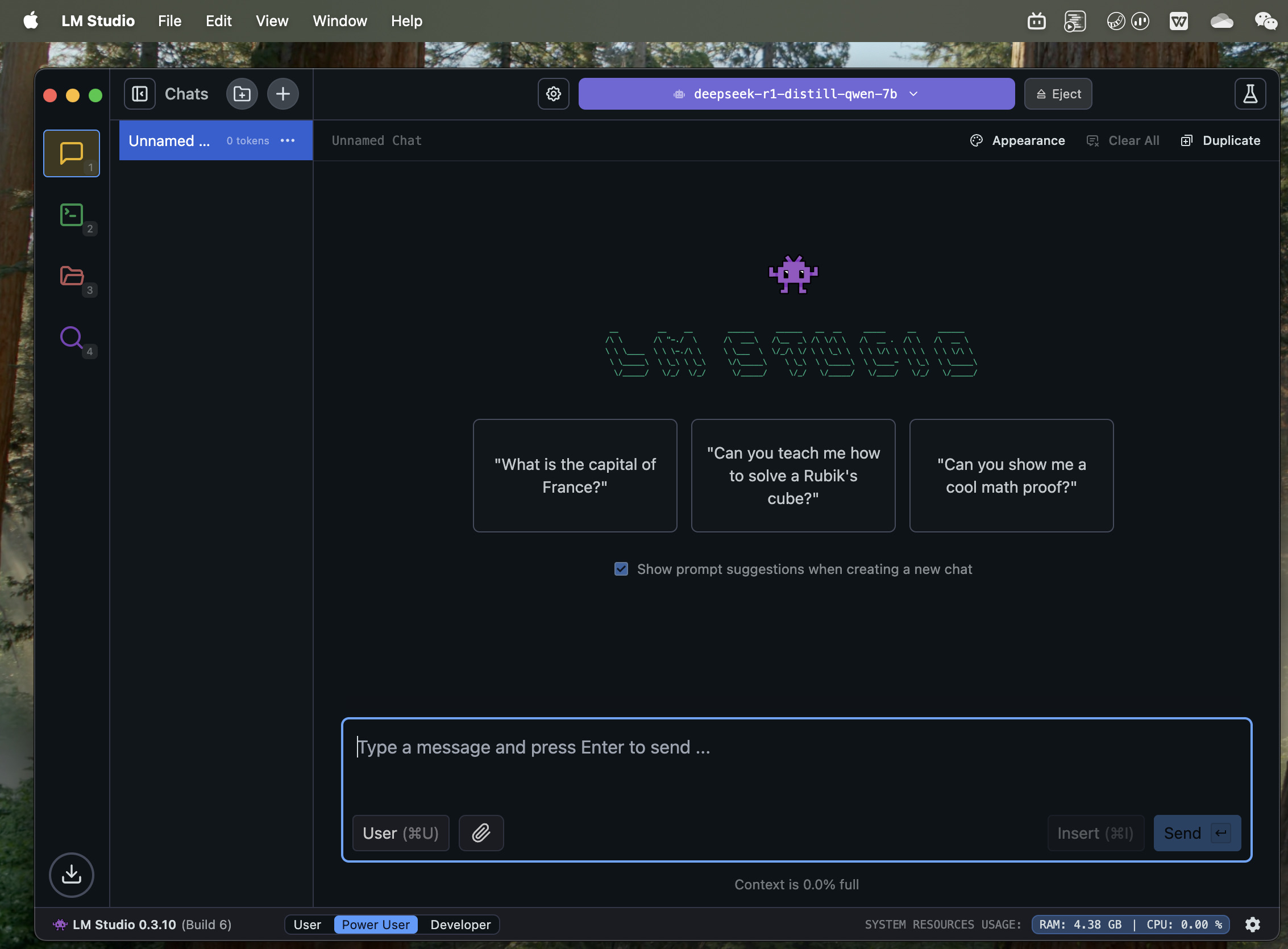
今天照例在单位发呆划水,用DeepSeek偶尔很卡,突然想到可以本地部署,于是用豆包搜了部署攻略,经过一番摸索,成功[调皮]如图三。
我用的加载模型软件是LM studio,除了部署dpsk,还可以部署llama(meta), qwen(阿里), mistral等等模型。我部署的这个应该是蒸馏过的,对算力要求比较低。然后我的电脑是2020年m1 pro乞丐版MacBook Pro,16g内存,dpsk模型平均每秒可以生成20tokens,用llama3.2平均每秒可以70tokens,都非常流畅,m3/m4更没问题了。Windows也可以部署,但不清楚对gpu要求高不高,写文章这会我正在pc上下载模型,有点慢,还没体验具体速度。
前面提到token,可能有些人还不太了解什么是token。可以把它理解为模型思考的最小输入输出单位,对应一个字或一个词,比如“我”,1个字可能是一个token,“孙悟空”,3个字也可能是一个token,但同样内容在不同模型,可能对应不同数量的token。大模型定价,一般就是按照输入输出的token数量来的。
每一个可部署的模型,参数数量是不一样的,这个deepseek模型参数是7b,即7 billion,70亿个。我大概试了30b以下的都提示兼容,但个别60-70b的模型,下载前就会提示可能对我的电脑太大了。大家如果有很nb的硬件,可以去尝试下。这也是为什么openAI的4.5模型、xAI的grok3对算力要求很高,因为他们的模型参数实在太多了。哪怕deepseek对算力要求不高,但目前需求实在太多,幻方已经没有足够的gpu满足所有计算需求了。
看,这就是我为什么说deepseek并不会打破算力需求,反而会进一步激发算力需求。举个比喻,当年2G时代,可能1m流量1块钱,我看几个gif图就用光了,现在5g时代,1gb才1块钱,流量价格便宜了1000倍,但现在的流量需求,却远超当年的1000倍,算力也是同理。
今晚早点写完,去洗澡了,大家早点休息$英伟达(NVDA)$

免责声明:上述内容仅代表发帖人个人观点,不构成本平台的任何投资建议。
- 艳阳高照天·2025-03-04太厉害了!👍点赞举报
- 老山古·2025-03-04阅点赞举报
- Xzhouz·2025-03-04[强]点赞举报