
AI估值循环的断层与救赎
2026年3月,硅谷知名风投Chamath Palihapitiya在其公司8090的All-In Podcast访谈中抛出了一个尖锐观点:"找不到任何一家企业真正靠AI赚钱"。这句话迅速在华尔街引发震荡,因为它戳破了当前AI繁荣表象下的核心困境.
Chamath的批评并非空穴来风。他披露了自己公司,一家致力于重写传统软件的AI原生企业,的真实财务数据:自2025年11月以来,AI成本增长超过三倍,公司正朝着每年1000万美元的AI支出迈进。更惊人的是成本增速,"成本每三个月增长3倍,但收入却没有同步增长".
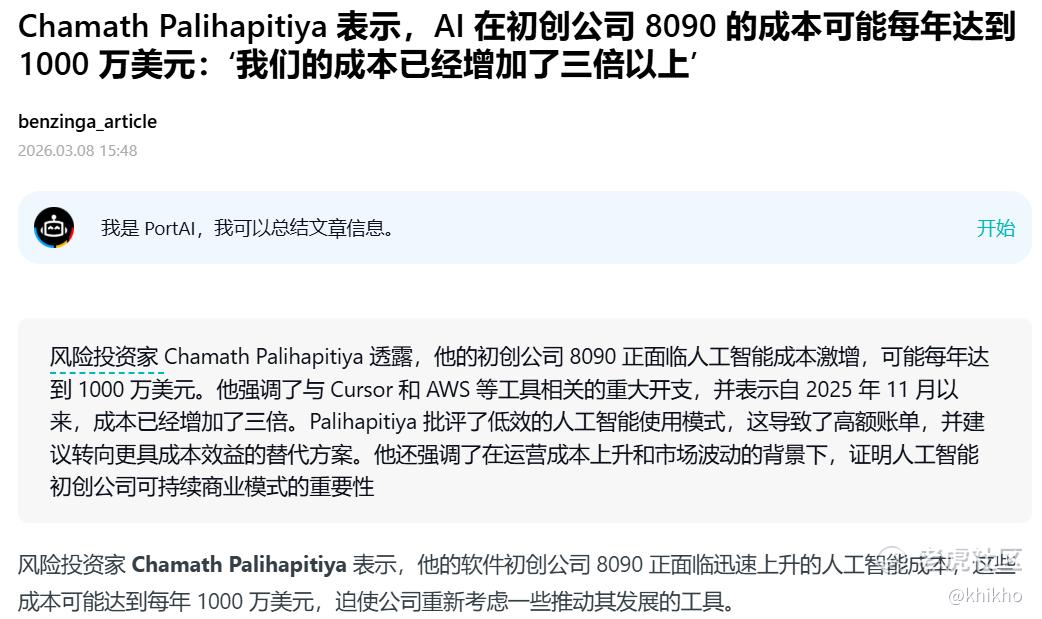
这种成本结构正在压垮企业端的AI应用。8090支付的AI账单包括:AWS的推理成本("极其巨大")、Cursor的订阅费用、Anthropic的API调用。Chamath直言不讳地指出:"感谢那些通过巨额投资为我们提供无限量token消费的VC们",这句话揭示了当前AI生态的畸形现状, 许多AI应用的"盈利"实际上是建立在VC补贴之上的伪盈利.
Chamath特别点名了AI编程工具Cursor。他发现Cursor的token账单高得离谱,正计划将团队迁移至Anthropic的Claude Code。Chamath提出了一个广为流传的隐喻:"LLM就像制冷技术本身,真正赚钱的是用它造可口可乐的公司"。这个比喻精准地划分了AI产业链的价值分层:
基础设施层(制冷技术)就像OpenAI、Anthropic等基础模型厂商,以及Nvidia等芯片供应商,对应"卖水人"角色;
应用层(可口可乐)指的是那些真正利用AI创造可规模化的盈利商业模式的企业。
Chamath的核心论点是:目前所有"淘金者"(应用层企业)都没有找到可持续的盈利模型。AI在企业端的部署呈现典型的负向单位经济学(Negative Unit Economics)特征:企业引入AI后,token成本持续攀升,但收入端并未产生相应增益,导致利润被侵蚀而非创造。
这与OpenAI/Anthropic的高收入并不矛盾,那是"卖水人"在赚钱,而非"淘金者"成功。Chamath的警告实质是:AI产业链的下游需求可能是虚假的,当前繁荣主要由模型公司自身的训练需求(自产自销)和VC补贴支撑,而非来自企业端真实的、可持续的付费意愿。
Chamath的观点呼应了华尔街日益增长的忧虑:支撑Nvidia、OpenAI、Anthropic高估值的需求循环,其底层可能是空的。从数据层面看,当前AI计算需求呈现明显的结构性失衡。Nvidia在Rubin平台发布时官方确认:"AI训练与推理需求正在爆炸式增长"。但细究之下,这种"爆炸"主要来自模型厂商自身:
训练需求:OpenAI、Anthropic、Google、Meta等前沿实验室为训练下一代模型(如GPT-5、Claude 4)持续采购GPU。虽然增长迅速,但企业端的大规模部署仍局限于实验性项目,缺乏稳定的付费场景。这种"自产自销"模式形成了危险的闭环:模型公司烧钱买GPU→GPU厂商收入暴涨→模型公司估值上升→继续融资烧钱。一旦企业端应用无法接棒,这个循环将面临断裂风险。
而Chamath的8090并非孤例。OpenCode创始人Dax Raad近期警告 "CFO们开始意识到AI账单的成本'你是说每个工程师每月要多花2000美元的LLM费用?'" Bain Capital Ventures的Amanda Huang指出,AI原生工具打破了SaaS的黄金法则:边际用户成本不再趋近于零。这种成本结构使得AI应用难以实现传统SaaS的规模化盈利。企业部署AI面临三重困境:
1.Token成本不可控:使用量与成本线性挂钩,难以预测月度支出;
2.效率增益难以货币化:AI提升的生产力往往体现在内部效率,难以转化为可定价的产品功能;
3.模型依赖风险:底层模型提供商的定价权导致应用层利润空间被持续压缩。
华尔街分析师开始质疑:如果企业端无法找到"AI原生利润机器"(AI-Native Profit Machines),当前AI基础设施的估值是否建立在沙滩之上。
那么,Rubin的10倍降本能否填补断层?能不能成为救赎呢?
面对估值循环的潜在断裂,Nvidia在2026年1月CES大会上发布的Rubin平台被视为最关键的破局变量。根据Nvidia官方新闻稿,Rubin平台通过"极致协同设计"(Extreme Codesign)整合六款新芯片,实现了革命性的成本突破。Nvidia公布的Rubin平台核心指标包括:
1.推理成本降低10倍:相比Blackwell架构,token推理成本下降最高达10倍;
2.训练效率提升4倍:训练MoE(混合专家)模型所需GPU数量减少至Blackwell的1/4;
3.产品交付时间:Rubin-based产品将于2026年下半年(H2)开始交付。
这些数字不是渐进式改良,而是代际跃迁。Nvidia官方明确将Rubin定位为"AI工厂"(AI Factory)的基础设施,旨在解决"agentic AI"(智能体AI)和MoE模型的规模化部署瓶颈。对于OpenAI、Anthropic等基础模型厂商,推理成本占其运营支出的核心部分。Rubin的10倍降本将直接提升API服务的毛利率;释放定价空间以应对开源模型竞争;改善烧钱速度,延长 runway 至商业化拐点。
OpenAI CEO Sam Altman在Rubin发布时表示:"智能随计算量扩展。当我们增加计算,模型变得更强大,解决更难的问题,为人们创造更大影响。Nvidia Rubin平台帮助我们持续扩展这一进程"。Anthropic CEO Dario Amodei也指出:"Rubin平台的效率提升代表了那种能够支持更长记忆、更好推理和更可靠输出的基础设施进步"。
更重要的是,Rubin可能改变企业端AI应用的经济学。当推理成本下降一个数量级,以下场景将变得经济可行:
大规模Agentic AI部署:处理长视频、法律文档、医疗记录等需要巨大上下文窗口的复杂任务;
AI自动化工具的普及:从编程助手(如Cursor、Claude Code)到客户服务、医疗诊断、金融分析的全流程自动化;
新SaaS++形态:AI-first B2B应用可以按传统SaaS模式定价,而不再受困于线性增长的token成本。
Aragon Research分析指出,Rubin的10倍token成本降低旨在使"agentic AI"在经济上可行,这对主流采用是"必需品而非奢侈品"。
然而,Rubin并非万能药。如果企业端无法找到可盈利的AI应用场景,单纯的成本下降只是将"无法盈利"变为"更便宜的无法盈利"。关键变量不是成本,而是需求的真实性。当前AI应用面临的核心问题并非"太贵",而是"无法创造可规模化的价值"。具体表现为:
价值捕获困难:AI提升的效率往往被客户视为"应该免费的基础功能",难以转化为付费意愿;
竞争同质化:基于相同LLM的应用缺乏差异化,陷入价格战;
组织适配成本:企业引入AI不仅是技术问题,更涉及流程重构、人员培训、合规审查,这些隐性成本往往被低估。
Rubin的10倍降本可以消除技术经济门槛,但无法自动创造商业价值。如果2026年下半年Rubin交付后,企业端仍未出现杀手级应用(Killer Use Case),AI估值循环仍将面临严峻考验。
基于上述分析,当前美股AI板块的投资逻辑需要重新校准。估值循环的当前状态,并非完全空心,但存在结构性断层。上游(芯片/模型)需求真实但存在"自产自销"风险,估值包含对未来企业端爆发的预期。中游(云/infra)受益于当前训练需求,但需观察企业端工作负载迁移速度。下游(应用)普遍面临单位经济学困境,Chamath的警告适用于绝大多数AI应用公司。
而Nvidia Rubin是目前唯一能从成本结构上打破这一僵局的技术变量。10倍的token成本下降若能在2026年下半年顺利交付,将为企业端AI应用的盈利创造必要条件,但仅是必要条件,而非充分条件。最终的破局取决于 是否有"AI让企业赚钱"的杀手级应用出现? 这是比Rubin技术参数更难以预测,却更为关键的变量。
朋友们觉得呢?[鬼脸]
[财迷]$老虎证券(TIGR)$ [财迷]
免责声明:上述内容仅代表发帖人个人观点,不构成本平台的任何投资建议。
- BerniceCarter·03-16 11:17Chamath观点犀利,AI应用难盈利啊!点赞举报
- 火火兔爸·03-16 21:09这篇文章不错,转发给大家看看点赞举报