
极视角「星际视觉语言大模型4B版本」深度解读:强性能、低幻觉、可落地

当大模型从技术尝鲜走向复杂实景,却常因图像理解失准、检测误差频发、关键结论易生幻觉而难以落地,更无法支撑核心业务决策。如何让大模型跳出「纸上谈兵」,真正扎根实地,实现看得准、靠得住、用得稳?
极视角基于十年技术沉淀与场景理解,自主研发面向产业的新一代多模态视觉语言大模型——星际视觉语言大模型(Stellaris-VL)。
本文将结合视频,深度拆解,看它如何凭借「强性能、低幻觉、可落地」硬核能力,切实解决产业真实业务难题。

三大亮点
1、强性能
核心能力进阶,从感知到认知的深度突破
星际视觉语言大模型具有八大能力,重点聚焦开放词汇目标检测(OVD)、指代表达理解(REC)与视觉问答(VQA)等关键能力维度,让大模型真正做到“理解深、看得懂、看得准”。

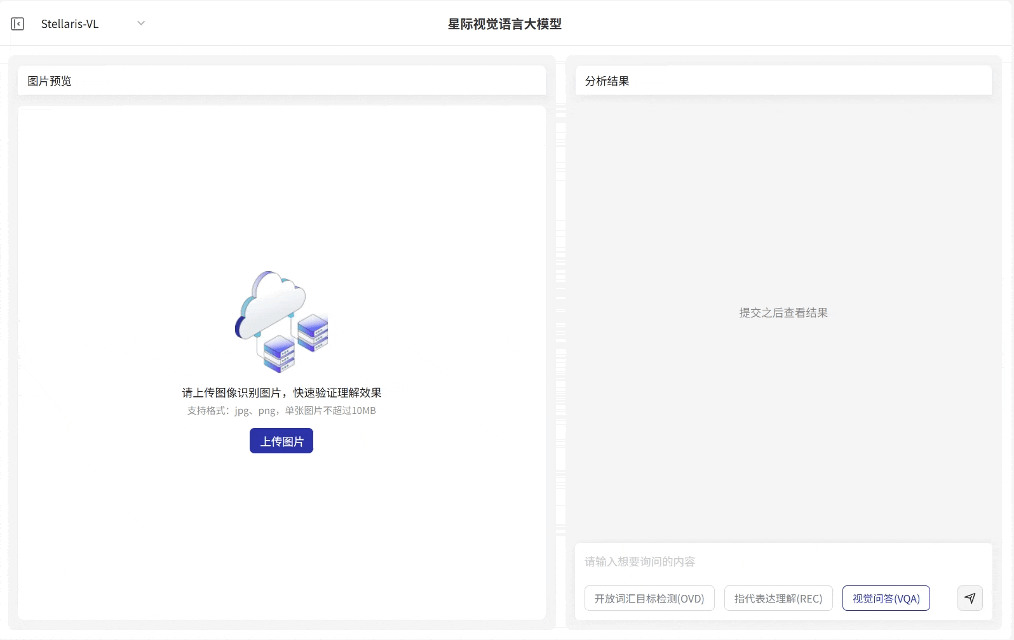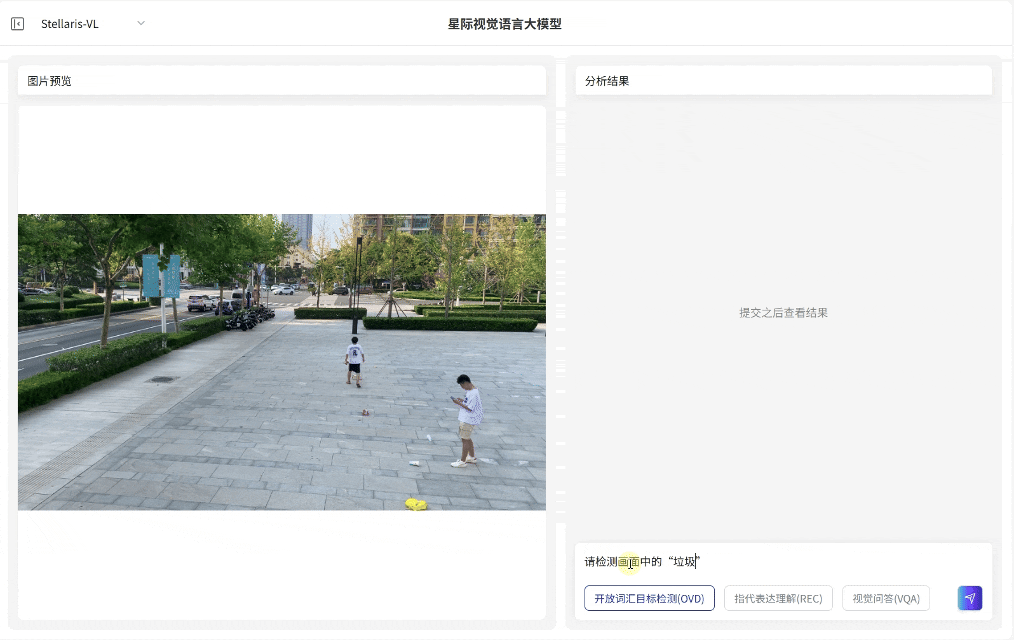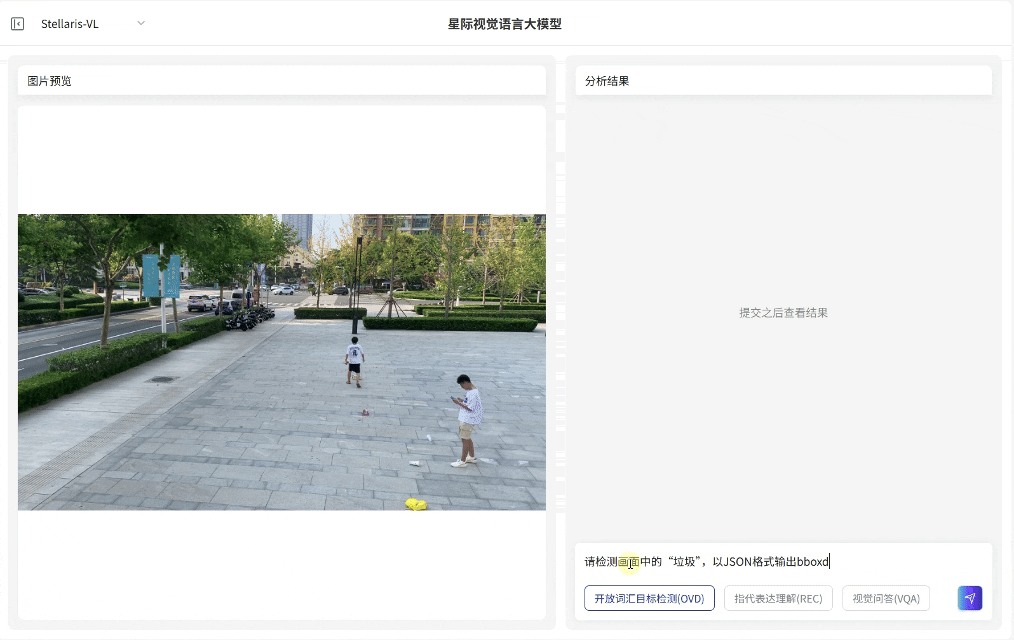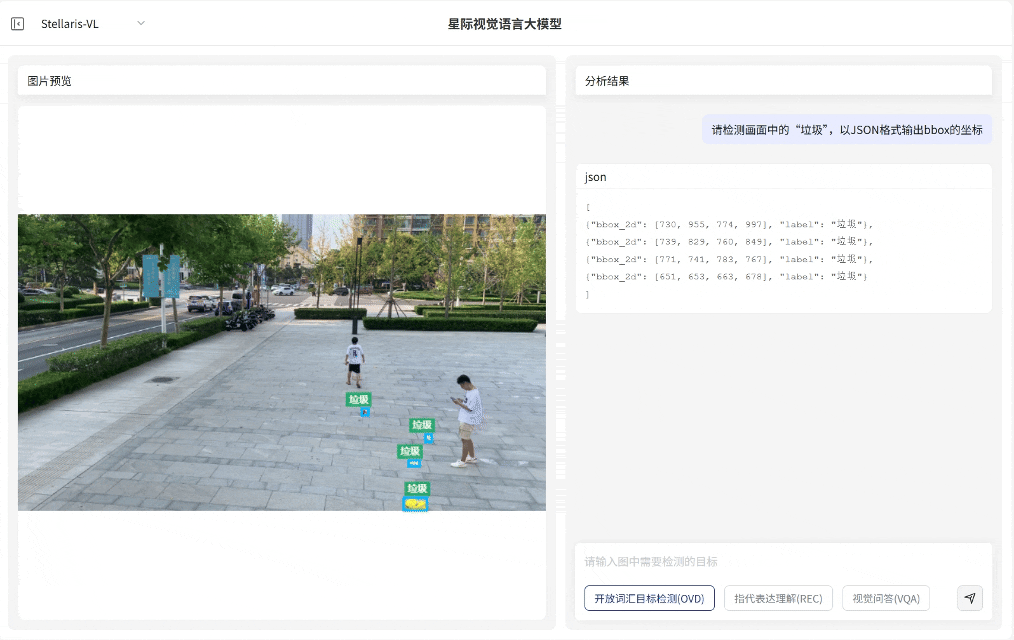
开放词汇目标检测(OVD):支持输入任意词汇指令,例如车辆、垃圾、危险物品、火焰等,即可识别对应目标并输出定位框,覆盖从生活到产业的"万物识别"需求。
指代表达理解(REC):支持解析复杂自然语言指令,具备精准定位特定目标的能力,输入短语级描述例如 “压线行驶的车辆”“河面上黄色的渔网” 等,即可快速识别对应目标并输出边界框坐标,满足复杂场景下目标定位需求。
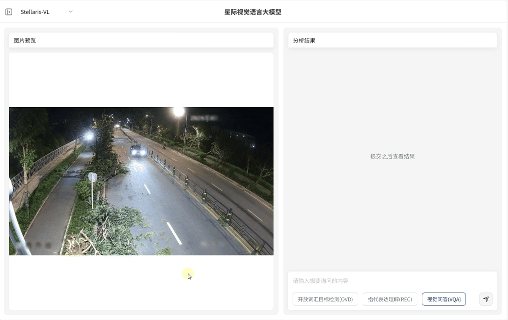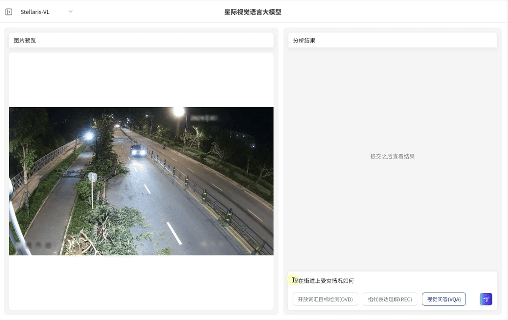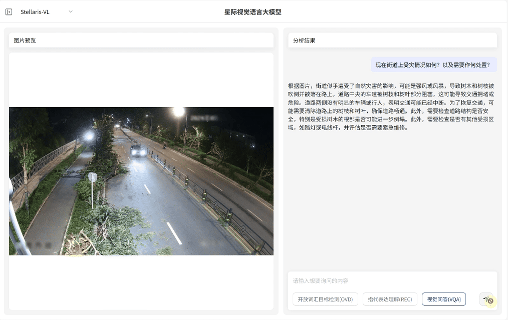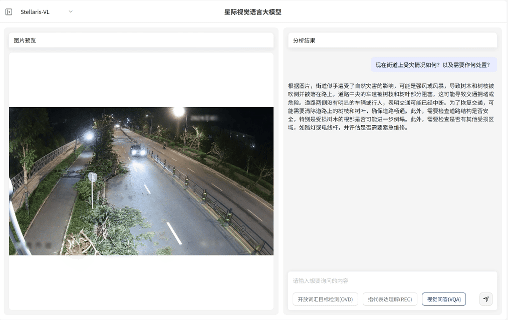
视觉问答(VQA):无需预设问题模板,支持基于图像内容的关联问答交互,即可快速输出画面关联解读、结构化分析和推理分析,覆盖状态研判、数量统计与关系推理等多维任务需求。
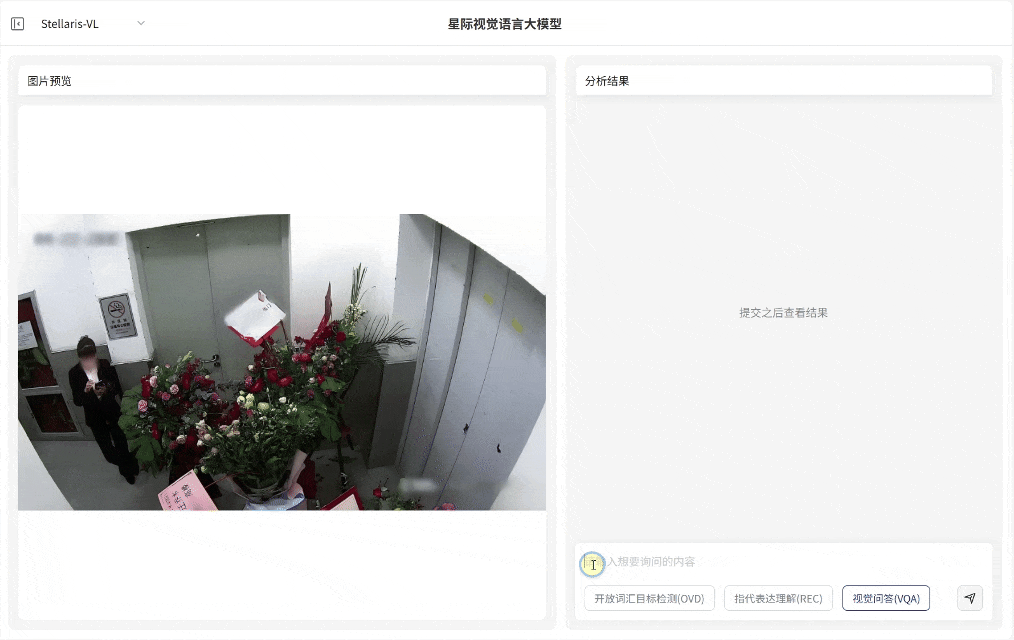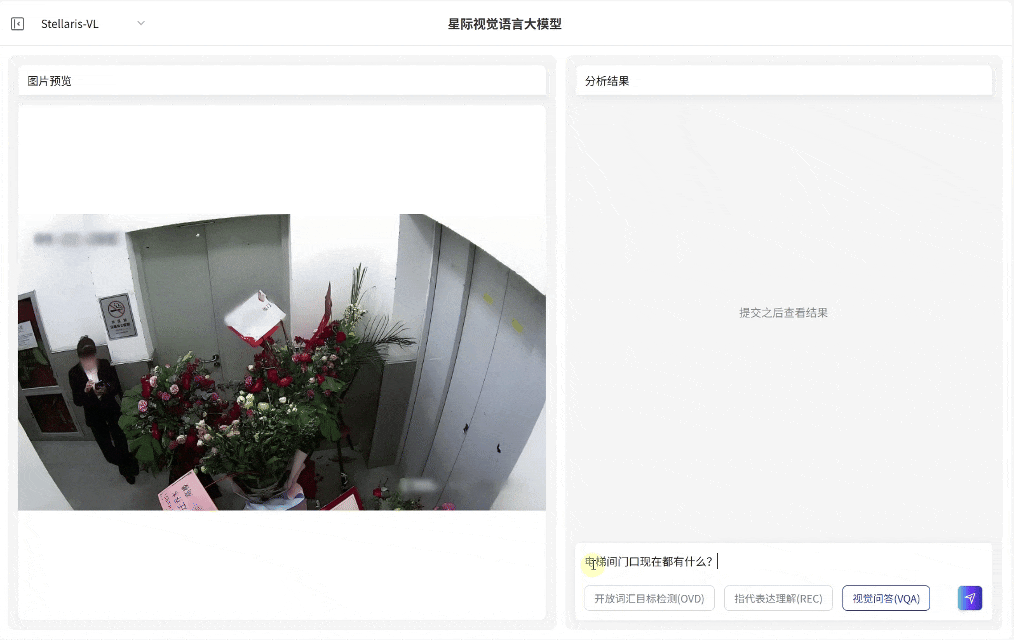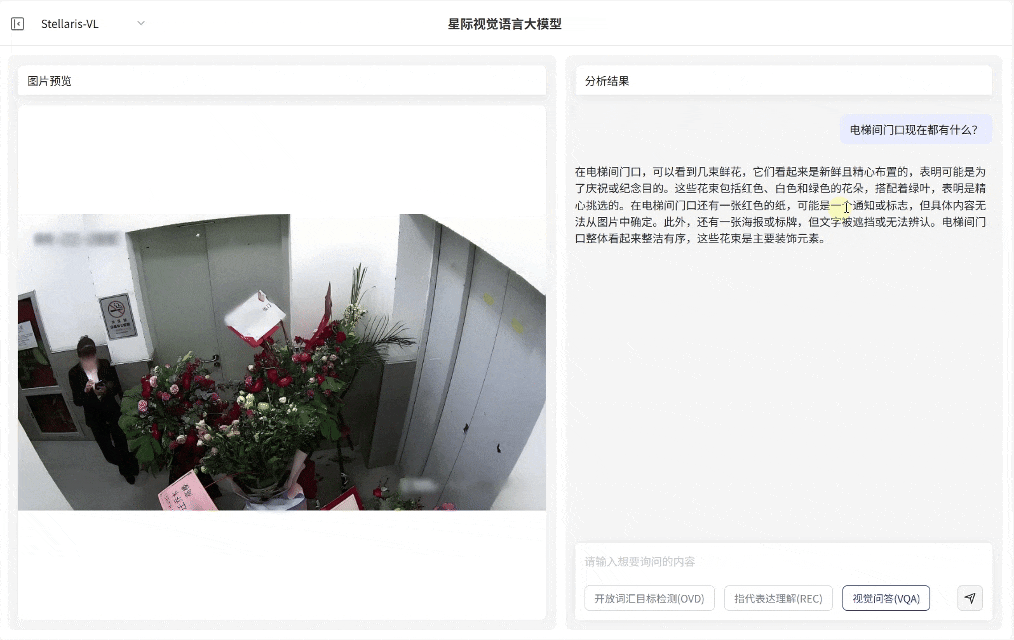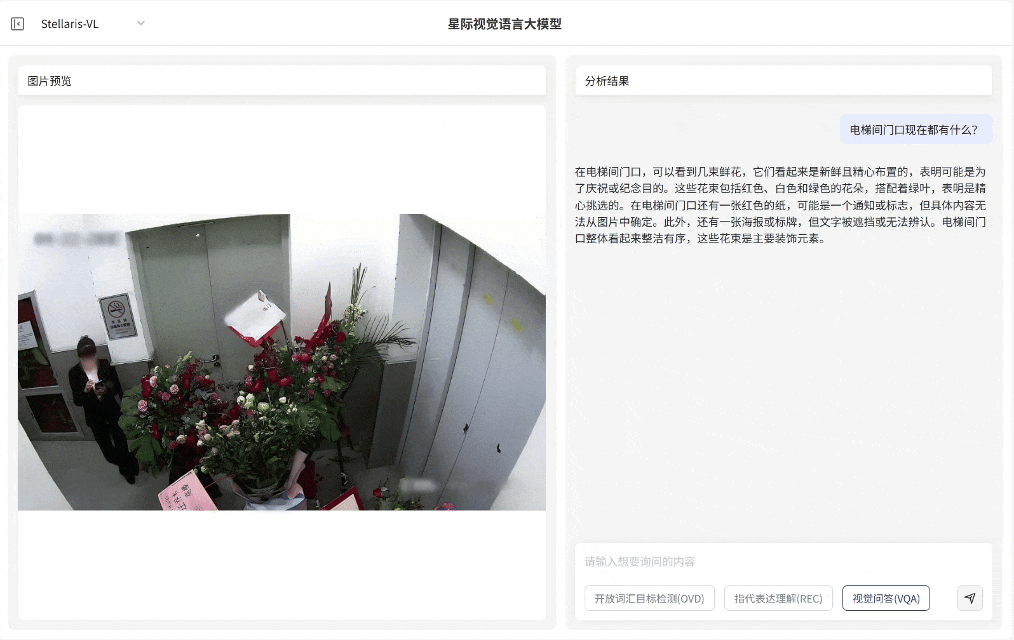
OCR与文档问答:能直接读取图片、票据、报告等图像文本信息,解析语义内容并输出分析。
图像描述:支持将视觉信息转化为文本描述,还原场景状态和多层次信息,辅助业务场景人工复核和决策。
2、低幻觉
源头保障,多重优化,看得准、说得对
大模型幻觉问题是产业落地的核心痛点与阻碍。为此,极视角从两个方面入手,系统性提升星际视觉语言大模型输出的准确性与稳定性。
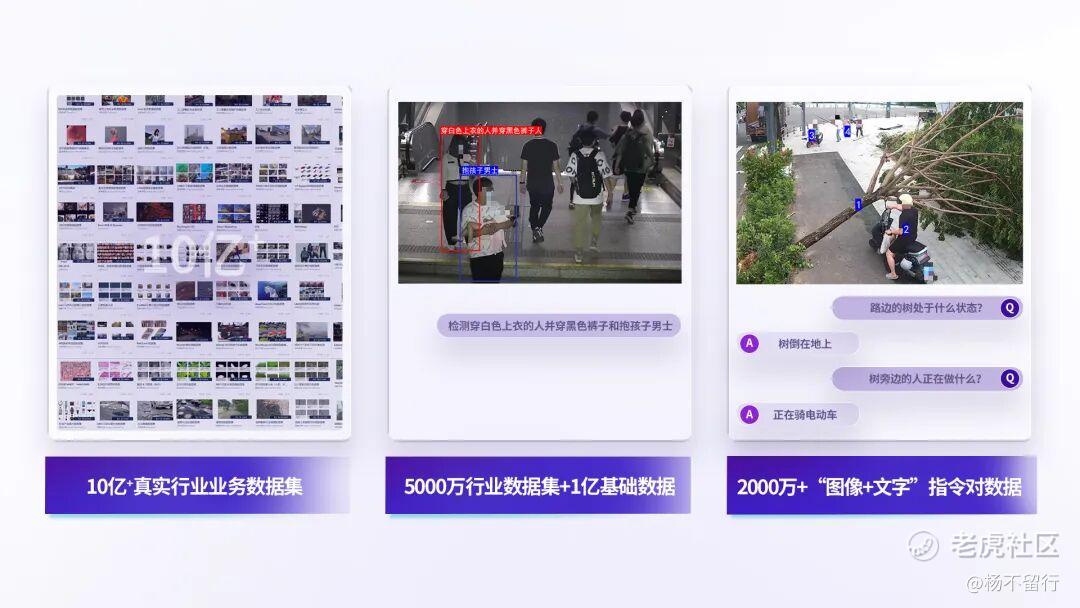
真实业务数据集源头保障
极视角采用多种训练模式,基于10亿+真实业务数据集,针对不同行业和业务匹配数据样本进行标注训练,让星际视觉语言大模型在复杂场景中实现高精度识别与稳定推理,有效降低模型幻觉与误判风险。
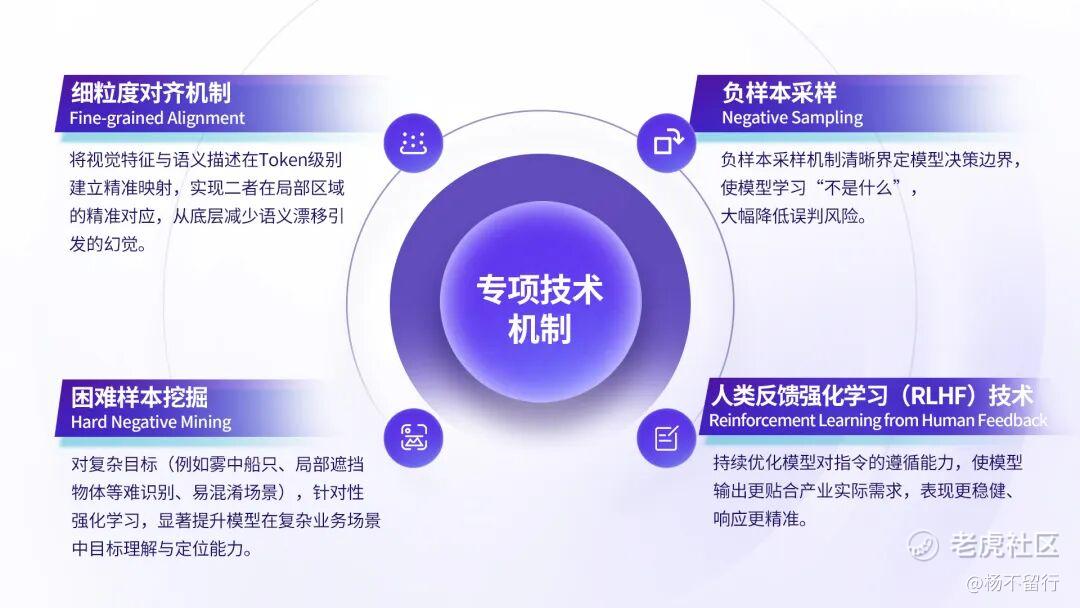
多重技术专项降低幻觉
极视角构建细粒度对齐、负样本采样等多维度专项技术机制,从技术层面进一步抑制幻觉,让星际视觉语言大模型整体表现更加准确、可靠。
3、可落地
4B版本兼顾性能与成本,灵活易用
边侧部署
星际视觉语言大模型4B版兼顾小体积与大能力,支持边缘端部署,可在单卡服务器流畅运行,本地完成图像解析与推理,在高并发环境下仍能保持低延迟、高可靠性输出。
便捷易用
星际视觉语言大模型可直接在极星平台使用:用户只需上传图像、输入中/英文提示词,一句话即可自定义模型,并可快速切换调用多种能力,灵活适配多种任务类型。极星平台提供简洁直观的可视化界面,让用户操作简单、高效。
架构特点
星际视觉语言大模型采用多模态融合的技术架构体系,将图像转换为视觉词,实现更强的跨模态理解与推理能力。
统一视觉编码:采用统一的视觉编码器,同时处理不同尺度的视觉特征。
目标框Token化:创新目标框相关Token生成技术,将目标任务转化为语言模型可理解形式。
精度显著提升:检测万物,相比传统方法,在任意目标检测精度上有显著提升。
精准增强平衡:添加专门的目标获取分支,增强模型的定位能力,同时不牺牲模型的理解能力,兼顾两种核心能力。
灵活扩展:模块化设计,核心模块可按需替换,快速调整推理或定位能力,适配不同需求。
场景应用演示
星际视觉语言大模型让产业领域“万物识别、即问即答”更高效、更普惠,大幅降低AI落地门槛,为千行百业的智能化升级提供核心AI基座,在智慧城市、智慧交通、智慧水务、智慧能源、智能制造等多领域展现出广阔的应用潜力。
开放词汇目标检测(OVD)
指代表达理解(REC)
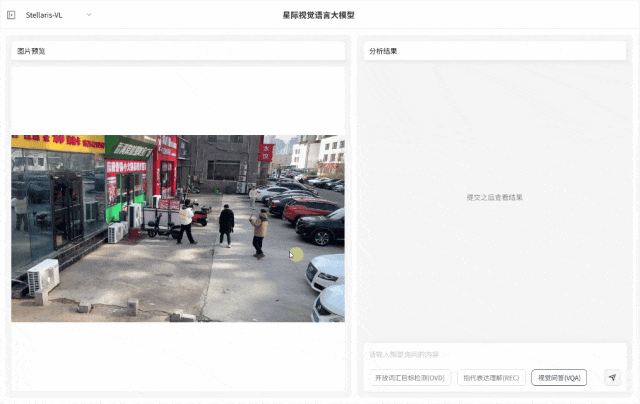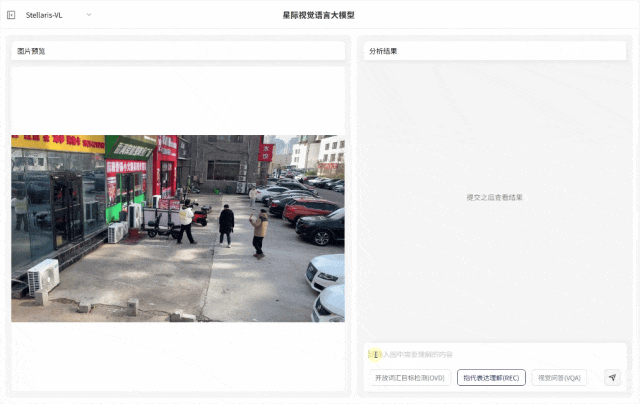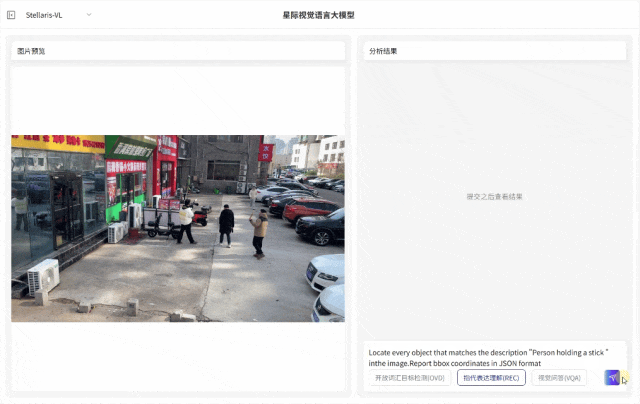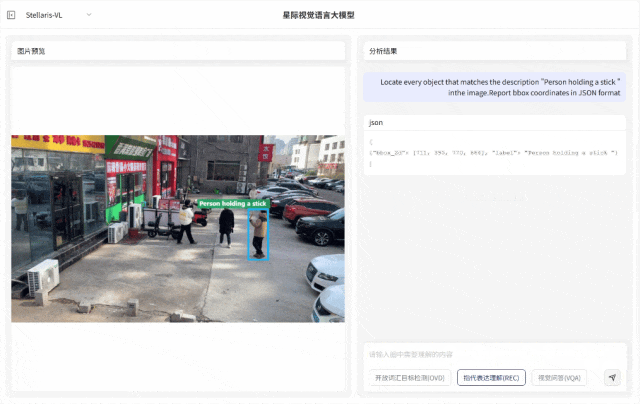
视觉问答(VQA)
OCR与文档问答

图像描述
星际视觉语言大模型的目标,是让大模型 “不止看见,更看懂业务”。接下来,极视角将继续深耕多模态大模型技术创新,持续升级大模型的感知、理解与执行能力,面向产业应用推出不同参数版本,加速AI技术与业务场景的深度融合和价值创造。
免责声明:上述内容仅代表发帖人个人观点,不构成本平台的任何投资建议。
