
美国老哥一句鲸鱼兄弟,DeepSeek版CC霸榜GitHub
昨天在网上冲浪时,我差点被这位老哥的散装中文笑死。发帖的哥们叫@Hunter Bown,是个音乐老师转码的美国独立开发者。
熟悉 DeepSeek 的人都知道,它的官方 Logo 就是一条深海蓝鲸,“鲸鱼兄弟”听着既有点莫名好笑又很形象。

虽然老哥中文有点烫嘴,但他的项目DeepSeek-TUI可不是来搞笑的。
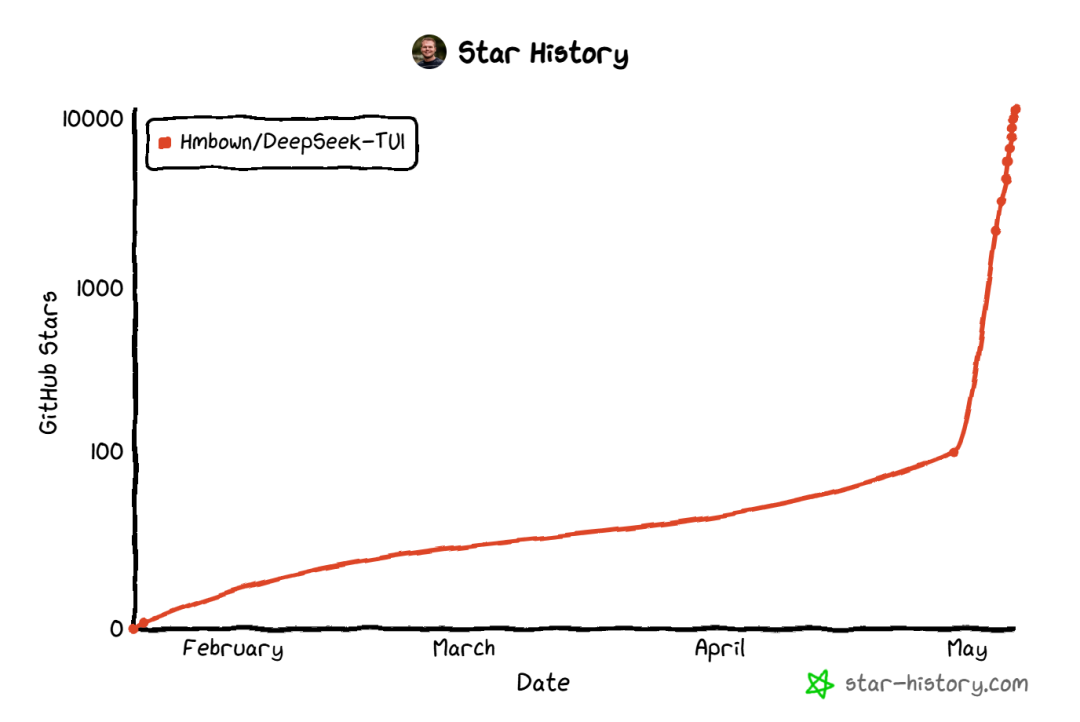
简单来说,他用AI搓了一个DeepSeek版Claude Code。短短几天内,这个项目狂揽1w+ GitHub Star,登上 Trending 榜首。
今天我们就来盘一盘,这个让全网鲸鱼兄弟直呼真香的项目,到底是个什么来头?
· · ·
网页版DeepSeek不够用吗?为什么非要折腾 Agent?
没有Agent,写代码的日常是这样的:代码跑出报错了 -> 复制报错 -> 打开网页贴给大模型 -> 等它吐出新代码 -> 复制回编辑器 -> 运行再次报错 -> 再次复制贴给模型……
哥,你这不是在用AI,你是在给AI当无情的搬运工。
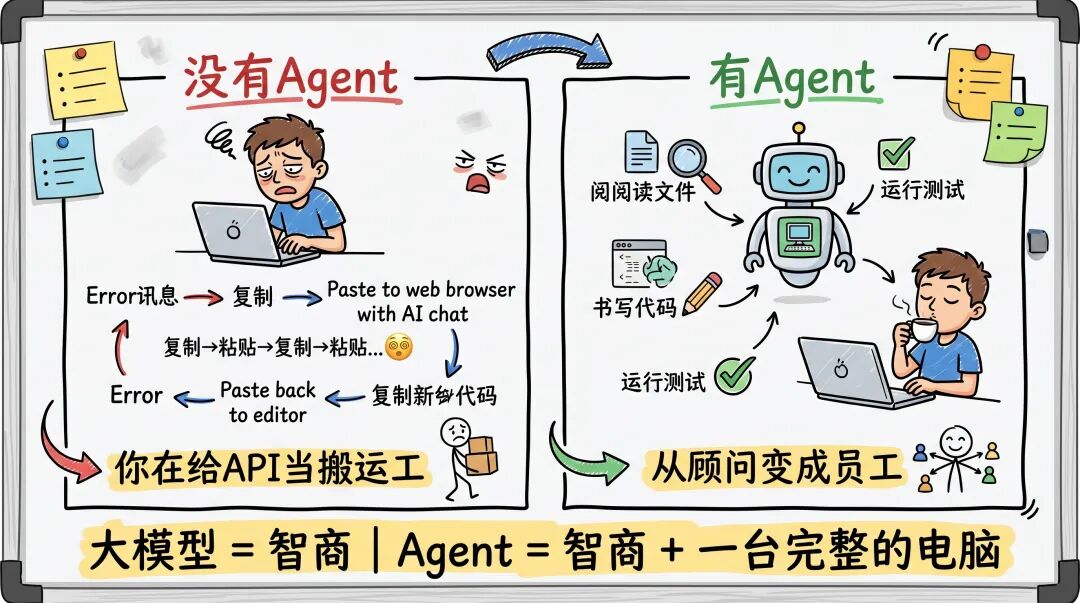
大模型本质上只是智商,它能理解、能回答,但它看不见你电脑里有什么,也动不了你任何东西。而 Claude Code这类Agent 做了一件事:给这个智商配了一台完整的电脑。
代码还是那个代码。但一旦有了读写文件的权限、有了执行命令的能力,它就从"顾问"变成了"员工"。你说"帮我把这个功能改一下",它自己去找对应的文件夹,自己读源代码,自己动手替换旧代码,改完自己跑测试看有没有报错。中间不需要你复制粘贴一次。
这就是我们要用 Agent 的原因——它能包办一整套连贯的体力活。
· · ·
Claude Code能调DeepSeek,为何要重造轮子?
这时候有动手能力强的朋友要问了:“网上不是有教程吗,让现成的 Claude Code 连上 DeepSeek 的 API 不就行了?干嘛还要重新造一个新Agent?”
这就是最大的坑。把保时捷的系统强行安在本田发动机上,指令对不上号是会出问题的。
如果你硬把 DeepSeek 塞进 Claude Code 的壳子里,立刻就会遇到各种“水土不服”:
首先是底层指令会跑偏,AI 会“消化不良”。
Claude的system prompt习惯用一套 XML 标签来封装工具调用指令(类似 执行搜索 的格式),而 DeepSeek虽然 API 层面能接收同样的请求,但模型本身更擅长 Markdown 和自然语言。
如果你强行把 Claude 那一套复杂的 XML 指令塞给 DeepSeek,它理解起来很吃力,经常会输出格式错误的文本,导致工具调用失败,最后整个程序卡死。
其次是省钱利器 cache_control 会失效。
用 API 写代码是很费钱的,所以 Claude 搞了个“提示词缓存”功能,通过发送 cache_control 这个特殊标签告诉服务器“这部分内容请帮我缓存起来,下次别算钱了”。
但问题是,DeepSeek 有自己独立的一套缓存判断逻辑,它根本不认识 Claude 发过来的这个标签。所以如果你用 Claude 的壳去调 DeepSeek,缓存省钱的功能直接就废了。
这也是为什么 Hunter Bown 要从零开始,写一套完全对接 DeepSeek 原生协议的代码。
· · ·
相比原版Claude Code,DeepSeek专属版强在哪?
不仅是原生适配,DeepSeek-TUI 真正让开发者蜂拥而至的,是以下四个硬核优势:
打破闭源巨头的“非英语 Token 税”
这是痛点中的痛点!很多人只知道 Claude 官方定价贵,但你不知道的是,中国开发者一直在被收着高昂的“隐形语言税”。
大模型计费是按 Token(词元)算的。分词器就像是一本密码本,Anthropic (Claude) 的密码本里英文多、中文少,导致一个中文词会被拆成好几个 Token 来计费。根据社区数据分析,用 Anthropic 的模型,处理中文文本的 Token 消耗是英文的 1.71 倍。也就是说,你哪怕只是在代码里写中文注释,每次调用都要凭空多交 71% 的钱!
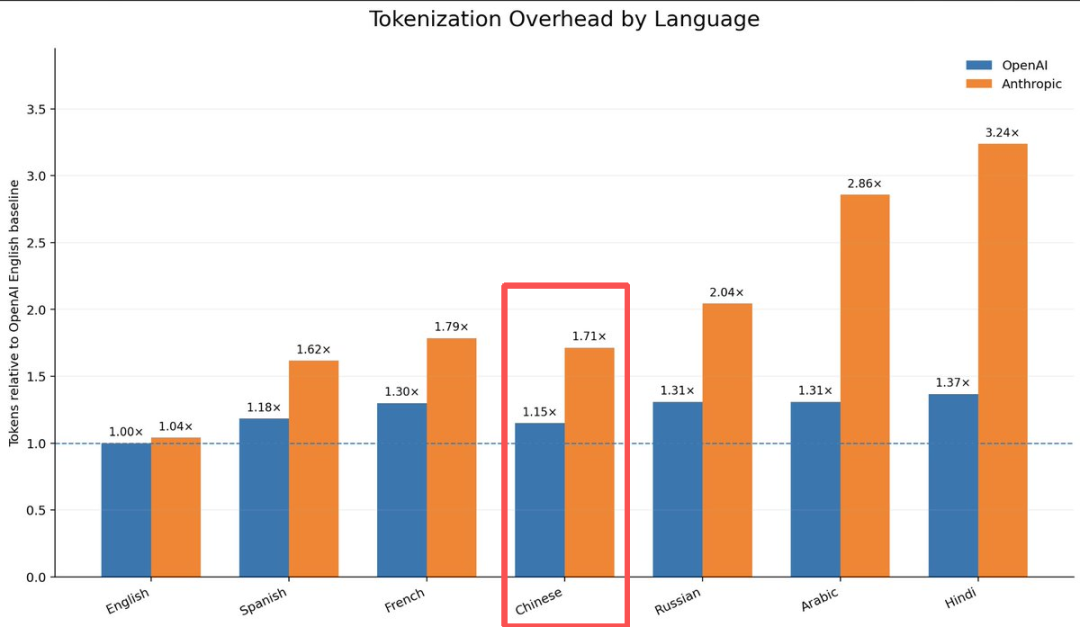
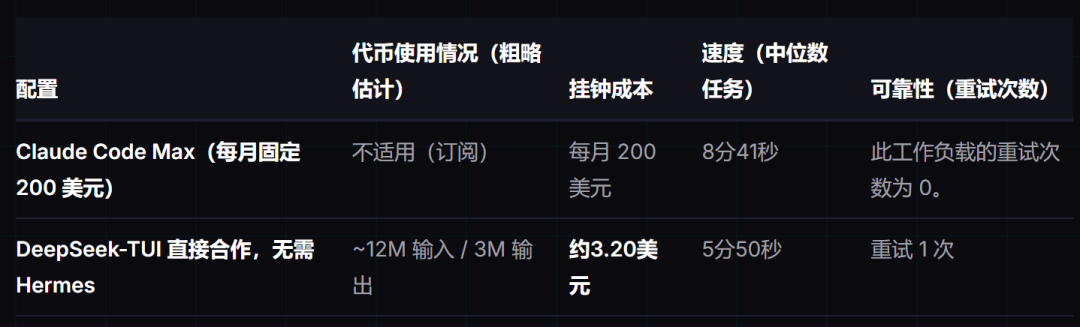
而国产的 DeepSeek 专门优化了中文分词字典,天然就避开了这种额外的成本开销。叠加其本身就极低的定价,综合算下来的差距十分夸张。据一家叫 AgentConn 的机构实测:同样完成一个 5 天的项目、修改 120 个文件,Claude Code 轻轻松松烧满 200 美元的额度;而 DeepSeek-TUI 直连跑完,只花了不到 3.20 美元!成本仅仅是前者的 2.3%。
把大模型的“深度思考”搬进命令行
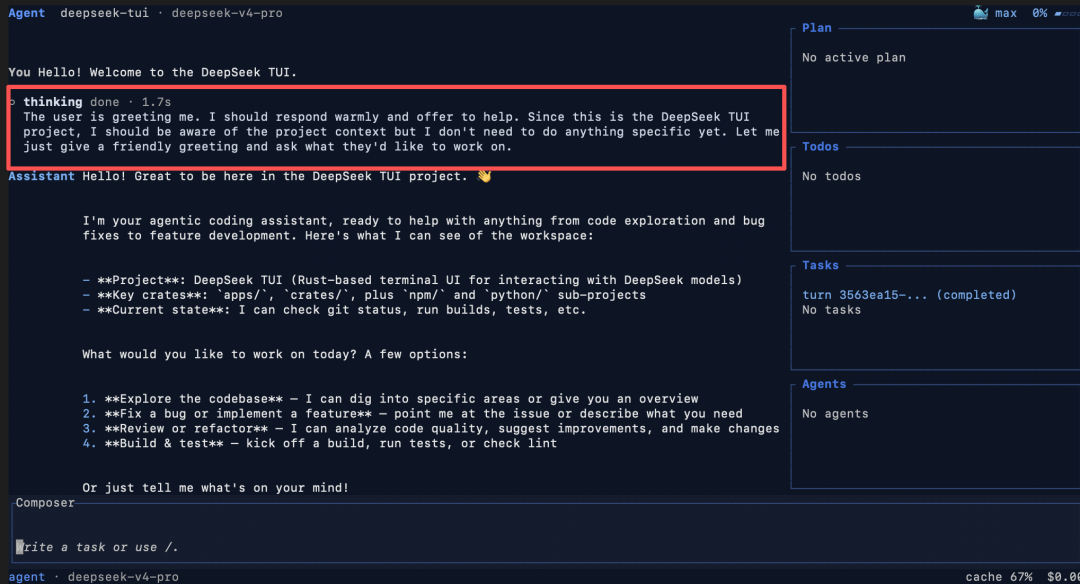
以前让 AI 处理一个大任务,屏幕经常卡在那里半分钟不动,你心里发毛,不知道它是死机了还是在干活。
DeepSeek-TUI 把 DeepSeek 标志性的“深度思考”过程,原封不动地搬到了代码终端里。你能实时看着它一行行输出推理过程(比如:“我先看看 A 文件……哦,A 文件没问题,那可能是 B 文件的依赖冲突了”)。这种透明度让人极具安全感。
省钱到骨子里的 Auto Mode(自动挡)
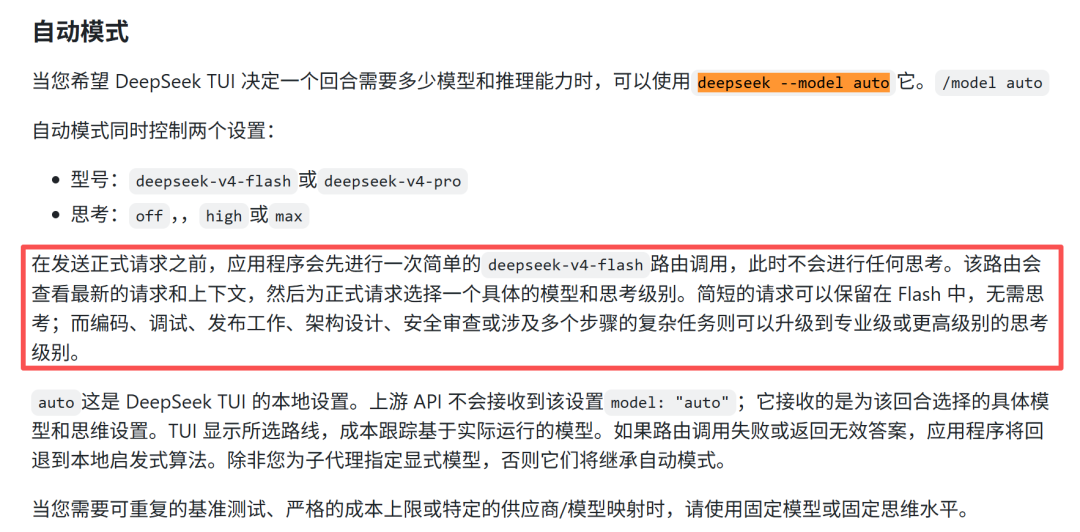
哪怕 DeepSeek 的 Pro 模型已经很便宜了,但能省则省。它内置了一个巧妙的路由机制:
当你敲下回车后,它不会马上执行,而是先花一点钱派一个便宜的 Flash 模型去快速评估一下你这句话的难度。如果 Flash 觉得只是改个拼写,它自己就顺手干了;如果觉得是个大重构,它就会自动切到最强最贵的 Pro 模型去干。
这就相当于先花几毛钱挂个“分诊号”,让小助手评估一下病情,再决定是看普通门诊还是专家号。
告别臃肿,Rust 编译的免安装利器
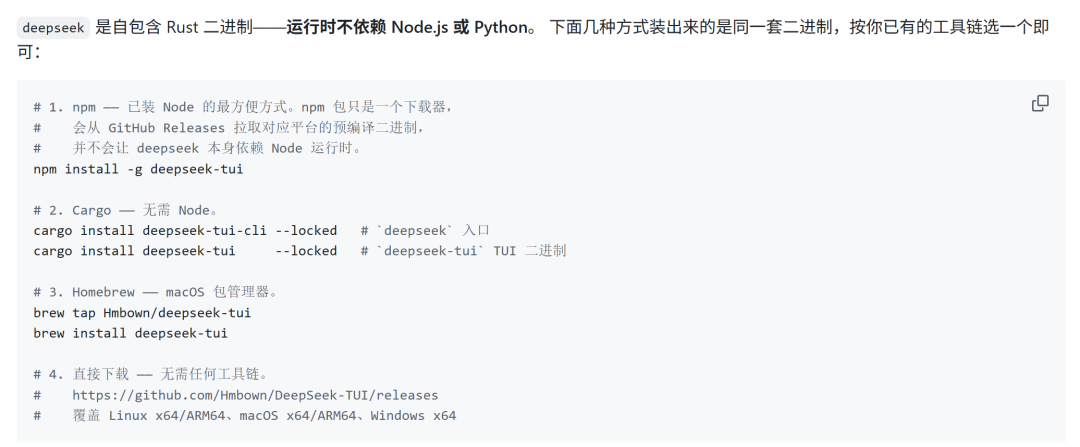
用过 Claude Code 的人都知道,它需要你先在电脑里安装一整套庞大的 Node.js 运行环境,就像是为了玩个游戏先装个Steam。而 DeepSeek-TUI 是用 Rust 语言编写的单一文件,它就像是一个绿色免安装软件,你下载下来直接就能运行,丝毫不拖泥带水。
· · ·
坦白局:到底好不好用
咱们说句客观的掏心窝子话:它并不是完美的。
如果你现在接手了一个史诗级的“屎山”项目,要跨越十几个微服务、几百个文件,进行极度复杂的深层逻辑重构——那我建议你,乖乖去用顶配模型。在超大规模的全局逻辑推理上,闭源巨头的标杆地位依然还在。部分试用过的开发者也反馈,在处理极端复杂任务时,DeepSeek 的指令遵循能力仍有差距。
但扪心自问,我们一年能遇到几次“史诗级重构”?
我们在开发中 90% 的日常,是高频的小修小补、补充单元测试、写技术文档,或者一次性看几十个小文件去排查一个小 Bug。在这个主阵地里,DeepSeek-TUI 的效率和性价比可以说惊为天人。
· · ·
最后
对于资金有限的独立开发者和中小团队来说,DeepSeek-TUI 提供了一个极其务实的选择。
顺便说一句,那个喊着“鲸鱼兄弟们”的美国老哥,据说现在不仅装上了微信,甚至已经在中文社区里和大家打成一片了。
项目地址:
https://github.com/Hmbown/DeepSeek-TUI
免责声明:上述内容仅代表发帖人个人观点,不构成本平台的任何投资建议。
