
AI 时代,GPU 有两种死法
如果给英伟达最先进的 GPU,配上十年前的内存和网络,会发生什么?
答案很简单:它几乎跑不起来。
这听起来很反直觉。大多数人觉得,AI 时代最重要的是 GPU。但研究越久我越发现——GPU 只是发动机。真正决定这台机器能不能跑起来的,是带宽。
先接上上一篇。
我在《存储,根本不是一个东西》里讲过一个判断:HBM 这种内存,表面上是在卖存储,本质上是在卖带宽。它值钱,不是因为能存多少,是因为能多快地把数据喂给 GPU。
当时这个判断,是存储篇的终点。但我后来发现,它其实是另一件事的起点。
因为"把数据快速喂给 GPU"这件事,HBM 只解决了一半。
为什么这么说?
你可以把一颗 GPU,想象成一个饭量大得惊人的大胃王。它一秒钟能吃下的数据,多到普通内存根本来不及端上桌。
如果数据喂得太慢,GPU 会饿死——算力再强,喂不饱,就是空转。你买了最贵的芯片,它却有一大半时间在干等着上菜。
这就是 HBM 要解决的问题:它是一条超宽的传送带,拼命把数据快速塞给 GPU,让它吃得饱。
而今天,这第一种死法,其实已经基本被解决了。 HBM 已经让 GPU 越来越吃得饱。
但一个新问题冒出来了:一颗 GPU,不够用了。
今天训练一个大模型,要成千上万颗 GPU 一起干活。这些 GPU 不是各吃各的,它们必须时时刻刻互相交换数据、对齐进度——像一个几万人的工厂,每个工位都要和其他工位实时同步。
于是第二种死法出现了。

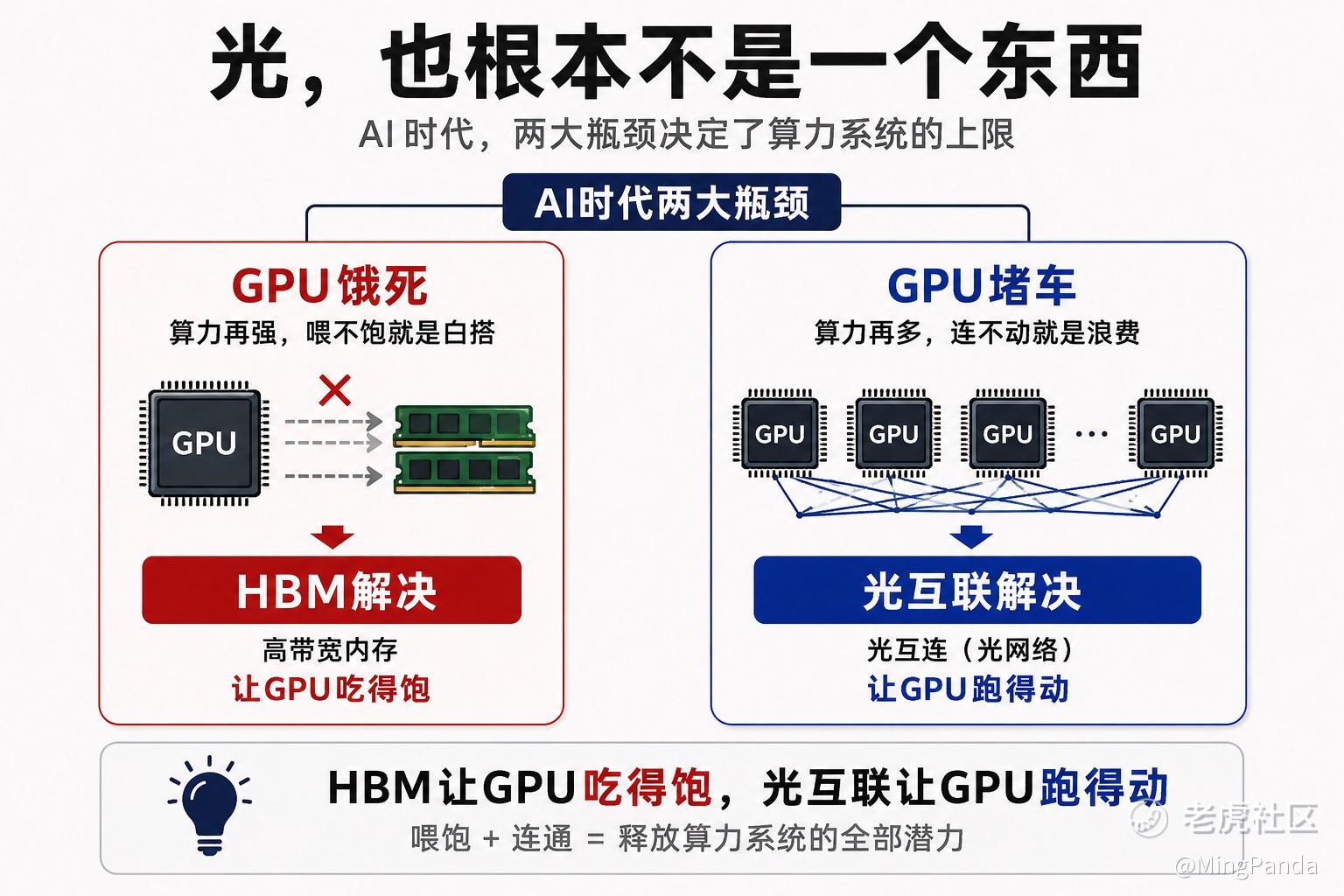
GPU 的第二种死法,叫堵车。
就算每一颗 GPU 都喂饱了,可它们之间如果连不动、传不快,整个集群照样跑不起来——几万颗最贵的芯片,卡在"互相传数据"这一步上,集体堵在路上。算力再多,连不动,就是浪费。
所以 GPU 其实有两种死法:
一种是吃不饱——饿死。一种是跑不动——堵车。
这两个问题,本质上是同一个东西在作怪:带宽不够。
只不过:
* 饿死,是喂数据的带宽不够——这是 HBM 已经在解决的。
* 堵车,是传数据的带宽不够——这是光互联要解决的。
而成千上万颗 GPU 之间的数据流动,正在成为 AI 时代新的瓶颈。
这就是为什么,黄仁勋专门提出过一个词,叫"I/O 墙"。
他的意思是:芯片的算力,可以靠制程和堆叠继续往上涨;但芯片和芯片之间传数据的能力,涨不了那么快。算力越堆越高,传输却撞上了一堵墙。
这堵墙,就是 GPU"堵车"的根源。 而推倒这堵墙的方法,就是把传数据的线,从铜,换成光。
如果说 HBM 的出现,是存储行业的"ChatGPT 时刻"——让所有人突然意识到"原来内存是在卖带宽";那么"I/O 墙",就是光互联的"ChatGPT 时刻"——让所有人开始意识到,连接芯片的能力,正在变得和芯片本身一样贵。
讲到这里,整件事就串起来了。
存储篇,讲的是带宽在哪里产生——HBM 让 GPU 吃得饱。光篇,要讲的是带宽如何流动——光互联让 GPU 跑得动。
一个解决"饿死",一个解决"堵车"。它们是 AI 算力系统的左膀右臂,缺一不可。
而"光互联"这件事,远比大多数人以为的复杂——它根本不是"光模块"一个东西,而是一整套正在重构的产业链。这也是为什么我要专门开一个光篇,一层一层把它拆开。
最后,留一个问题给你,也给我自己。
存储篇研究到最后,我们发现一件事:真正赚走大部分利润的,不是所有存储公司,而是 HBM——是海力士、是那条最窄、最贵的赛道。
那么光篇呢?
当资本市场所有人都盯着光模块的时候,真正赚走大部分利润的,会不会根本不是光模块?
是被称作"光互联心跳"的激光器?是把光直接做进芯片的硅光?是决定成败的先进封装?还是某个我们现在还没看清的环节?
这正是接下来几篇,我想和你一起拆开看的。
因为 AI 带来的最大变化,从来不是创造了新公司,而是重新定价了整个旧世界——这一次,轮到"光"了。
下一篇,我们先回答一个最基础、却很少有人讲清楚的问题:为什么说 AI 集群,根本不是一堆 GPU,而是一张带宽网络?
实盘观察,不是投资建议。
AI世界 vs 旧世界·光篇
① AI 时代,GPU 有两种死法(本篇)
② AI 集群不是一堆 GPU,而是一张带宽网络 (预告)
③ 铜,为什么突然不行了? (预告)
④ 为什么英伟达正在把铜换成光? (预告)
⑤ 光模块不是终点,钱正在往哪里搬?(预告)

免责声明:上述内容仅代表发帖人个人观点,不构成本平台的任何投资建议。
