
上一篇我们说,GPU 有两种死法:吃不饱(饿死),和跑不动(堵车)。
HBM 解决了第一种。而第二种——成千上万颗 GPU 之间"跑不动"的问题——要靠光互联。
但在讲光之前,得先搞清楚一件事:这些 GPU 到底是怎么连在一起的?
因为大多数人对"AI 算力"的想象是错的。
很多人以为,一个 AI 数据中心,就是"一大堆 GPU 堆在一起"。芯片越多,算力越强。
这个想象,少了最关键的一半。
真实的 AI 集群,不是一堆 GPU,而是一张网——一张让这些 GPU 互相传数据的"带宽网络"。
打个比方。一个万人工厂,光招一万个工人是没用的。如果工人之间没有通道、没有传送带、没法互相递东西,那这一万人不是一个工厂,只是一万个各干各的人。
GPU 也一样。把一万颗 GPU 摆在机房里,如果它们之间传不动数据,那它们就不是"一台超级计算机",只是一万颗互相不说话的芯片。
让它们变成"一台机器"的,不是 GPU 本身,是连接它们的那张网。
那这张网长什么样?
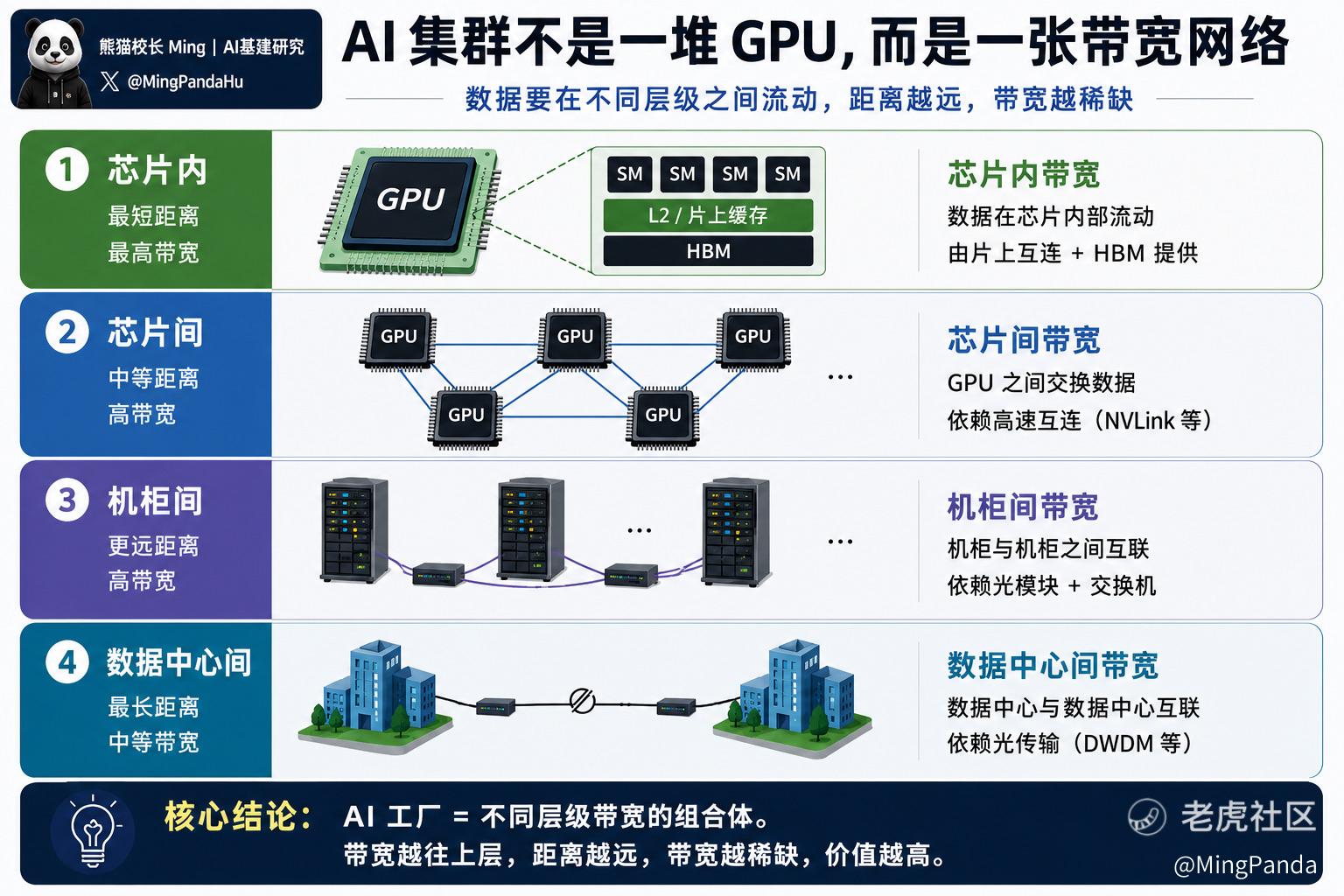
它其实是四层,按"数据要传多远"一层层往外扩。距离越远,带宽越稀缺,也越贵。
第一层,芯片内——最短的距离,最高的带宽。
数据在一颗 GPU 内部流动,从计算单元到它自己的内存。这一层的带宽,主要靠 HBM 提供——就是上一篇说的,让 GPU 吃得饱的那条超宽传送带。这是带宽最充裕的一层,因为距离最短。
第二层,芯片间——GPU 和 GPU 之间。
同一台服务器里,几颗、几十颗 GPU 要互相交换数据。这一层靠的是高速互联(比如英伟达的 NVLink)。距离一拉远,带宽就开始变得金贵。
第三层,机柜间——一个机柜和另一个机柜之间。
成百上千颗 GPU,装在不同的机柜里,机柜之间要连起来。到这一层,电信号已经传不动了,必须开始用光——这就是光模块的主战场。
第四层,数据中心间——一栋楼和另一栋楼,甚至一个城市和另一个城市之间。
当一个数据中心装不下,就要把多个数据中心连成一个更大的系统。这是最长的距离,靠的是长距离的光传输。
看懂这四层,你就会发现一个反直觉的事实:
AI 工厂的本质,不是算力的堆叠,是带宽的组合。
从芯片内到数据中心间,每一层都是一种带宽。距离越往外,带宽越稀缺,也越贵。
而"光"这个东西,恰恰是从第三层(机柜间)开始登场,越往外越重要。这也是为什么,AI 越往大集群发展,光就越关键——因为集群越大,要跨越的距离就越远,而远距离的带宽,只有光做得到。
所以回到那句话:AI 集群不是一堆 GPU,而是一张带宽网络。
你买了多少颗 GPU,决定的是这个集群的"理论算力上限"。 但这些 GPU 之间的带宽够不够,决定的是这个上限能不能真正发挥出来。
很多时候,限制一个 AI 集群的,不是它有多少算力,而是它的"网"够不够宽。
下一篇,我们要钻进第三层和第四层之间,回答一个被很多人忽略、却正在发生的大事:
为什么用了几十年的铜线,突然就不行了?为什么 AI 集群非得把铜换成光不可?
这背后,是一堵谁也绕不开的物理墙。
实盘观察,不是投资建议。
$迈威尔科技(MRVL)$ $Lumentum Holdings Inc.(LITE)$ $COHERENT(COHR)$
免责声明:上述内容仅代表发帖人个人观点,不构成本平台的任何投资建议。
